第2章 基礎知識
パフォーマンスチューニングを行う際には、そのアプリケーションの全体を調査し、修正する必要があります。したがって効果的にパフォーマンスチューニングを行うためには、ハードウェアから3Dのレンダリング、Unityの仕組みに至るまで幅広い知識が求められます。そこでこの章では、パフォーマンスチューニングを行うために必要な基礎知識についてまとめます。
2.1 ハードウェア
コンピューターのハードウェアは主に、入力装置、出力装置、記憶装置、演算装置、制御装置という5つの装置から構成されます。これらをコンピューターの五大装置と呼びます。この節ではこれらのハードウェアのうち、パフォーマンスチューニングを行う上で重要なものについて、その基礎知識をまとめます。
2.1.1 SoC
コンピューターはさまざま装置で構成されています。代表的な装置としては、制御や演算を行うためのCPU、グラフィックスの計算を行うためのGPU、音声や映像のデジタルデータを処理するDSPといったものが挙げられます。大半のデスクトップPCなどでは、これらは別々の集積回路として独立しており、それらを組み合わせることでコンピューターを構成します。これに対してスマートフォンでは、小型化や省電力化のためにこれらの装置が1つのチップ上に実装されています。これをSystem-on-a-chip、すなわちSoCと呼びます。
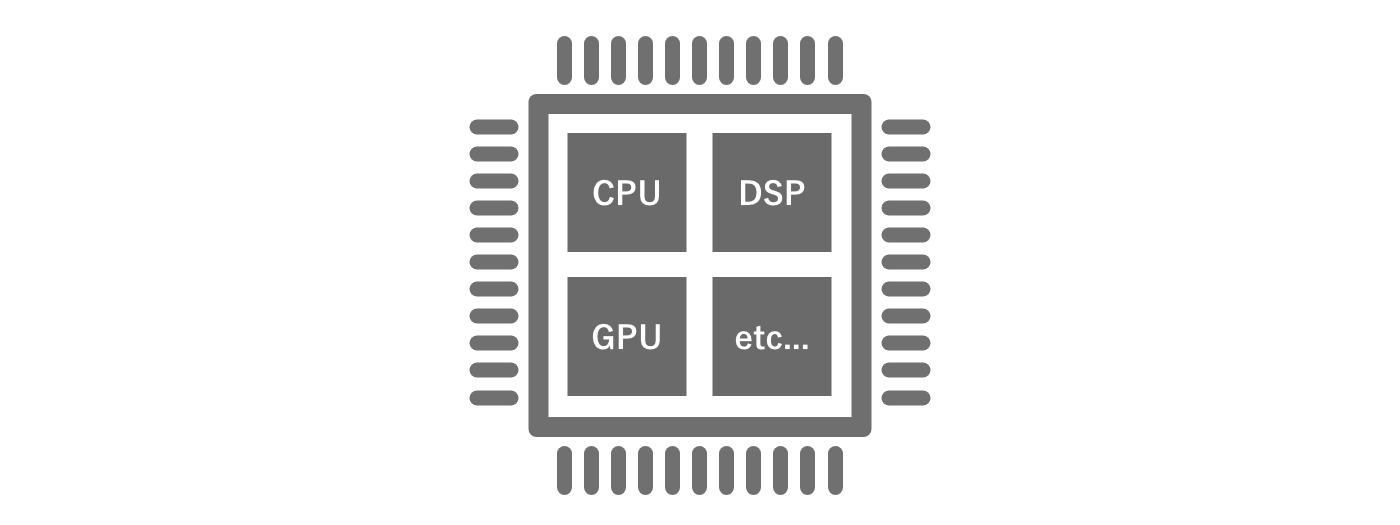
図2.1: SoC
2.1.2 iPhone・AndroidとSoC
スマートフォンはその機種によって搭載されているSoCが異なります。
たとえばiPhoneには、Apple社により設計されているAシリーズと呼ばれるSoCが使用されています。このシリーズはA15のように、「A」という文字と数字の組み合わせによる命名がされており、バージョンアップに伴って数字が大きくなっています。
これに対して多くのAndroidではSnapdragonと呼ばれるSoCが使用されています。これはQualcommという会社が製造しているSoCで、Snapdragon 8 Gen 1やSnapdragon 888のように命名されます。
また、iPhoneがApple社により製造されているのに対し、Androidはさまざまなメーカーが製造しています。このため、Androidには以下の表2.1に示すようにSnapdragon以外にもさまざまなSoCが存在します。Androidで機種依存の不具合が起こりやすいのはこのためです。
表2.1: Androidの主要なSoC
| シリーズ名 | メーカー | 搭載されている端末の傾向 |
|---|---|---|
| Snapdragon | Qualcomm社 | 幅広い端末で使用されている |
| Helio | MediaTek社 | 一部の廉価端末で使用されている |
| Kirin | HiSilicon社 | Huawei社製の端末 |
| Exynos | Samsung社 | Samsung社製の端末 |
パフォーマンスチューニングを行う際には、その端末のSoCに何が使用されていて、それがどのようなスペックのものなのかを理解することが重要です。
Snapdragonの命名はこれまで、「Snapdragon」という文字列と3桁の数字の組み合わせが主流でした。
この数字には意味があります。800番台はフラッグシップモデルで、いわゆるハイエンド端末に搭載されます。ここから小さい数字になるほど性能と価格が低下し、400番台になるといわゆるローエンド端末になります。
たとえ400番台であっても発売時期が新しいほど性能が向上するため一概には言えませんが、基本的には数字が大きいほど性能が高いとみなすことができます。
さらに、この命名規則だと近いうちに番号が足りなくなってしまうため、今後はSnapdragon 8 Gen 1のような命名に変更することが2021年に発表されました。
このような命名規則については端末の性能を判別するための指標となるため、パフォーマンスチューニングの際には覚えておくと便利です。
2.1.3 CPU
CPU (Central Processing Unit)はコンピューターの頭脳とも言うべき存在で、プログラムの実行はもちろん、コンピューターを構成するさまざまなハードウェアとの連携も行っています。実際にパフォーマンスチューニングする場合に、CPUの中でどういう処理が行われてどういう特性があるかを知ることで役立つので、ここではパフォーマンス観点で説明します。
CPUの基本
プログラムの実行速度を決めるのは単純な演算能力だけではなく、複雑なプログラムのステップをいかに高速に実行できるかどうかです。たとえばプログラムの中には四則演算もありますが、分岐処理もあります。CPUにとっては次にどの命令が呼び出されるかは、プログラムを実行するまではわかりません。そこでCPUは、さまざまな命令を高速に連続で処理できるようハードウェアが設計されています。
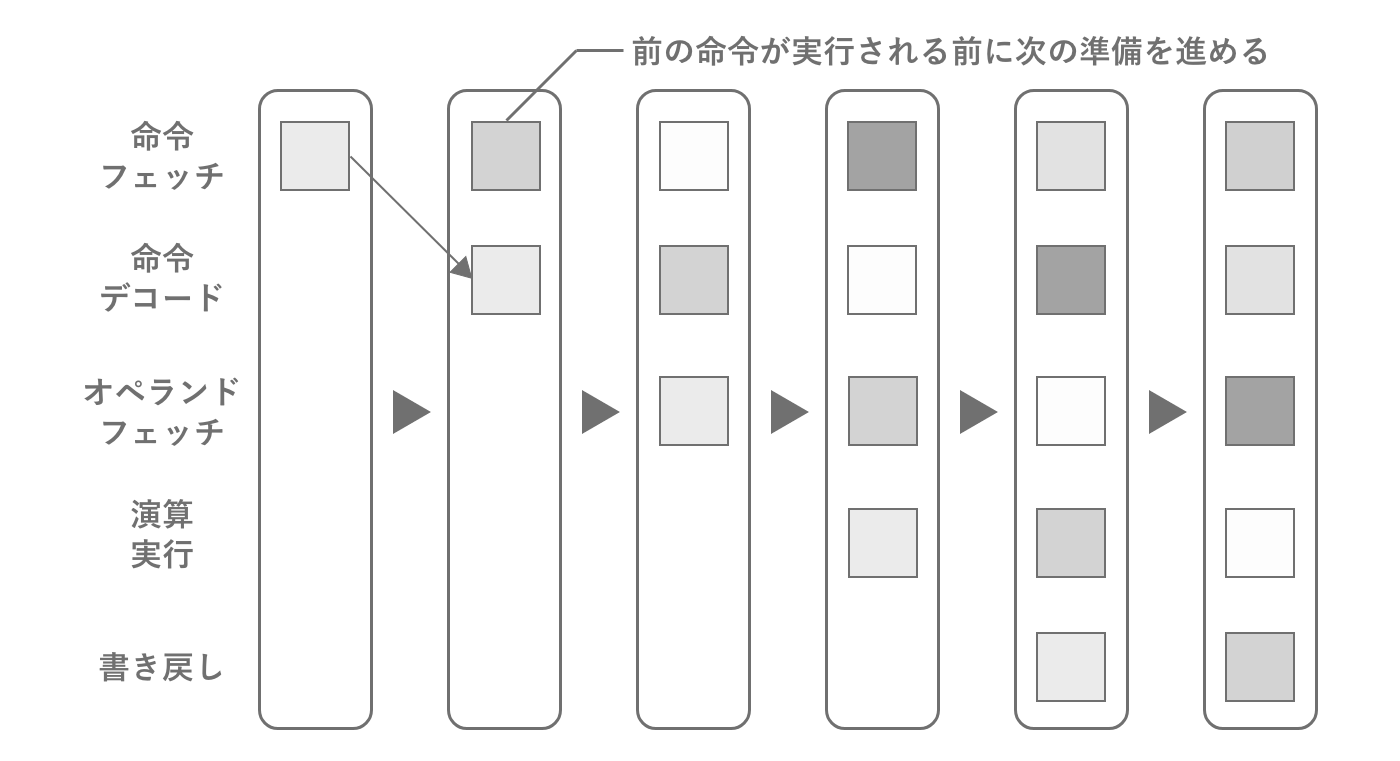
図2.2: CPUのパイプライン・アーキテクチャ
CPU内部での命令が処理する流れをパイプラインと呼び、パイプラインの中で次の命令を予測しながら処理されています。次の命令がもし予測されていない場合は、パイプライン・ストールと呼ばれる一時停止が発生し一度リセットされます。ストールする原因の大部分は分岐処理です。分岐自体もある程度は結果を先読みしていますが、それでも間違えることはあります。内部構造を覚えなくてもパフォーマンスチューニングは可能ですが、こういうことを知っておくだけでもコードを書く際にループの中で分岐を避けるなどが意識できるようになります。
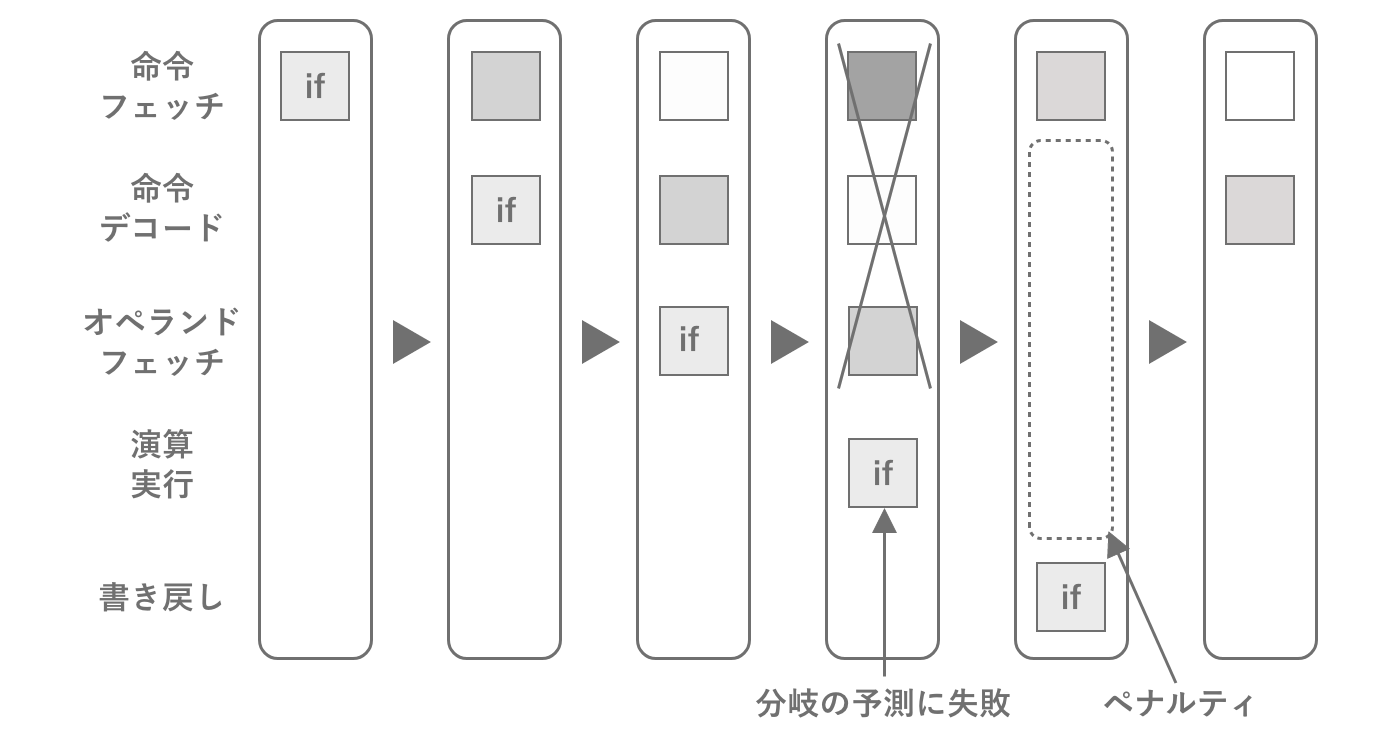
図2.3: CPUのパイプライン・ストール
CPUの演算能力
CPUの演算能力は、クロック周波数(単位はHz)とコア数で決定されます。クロック周波数は1秒間に何回CPUが動作できるかを表します。そのためクロック周波数が高ければ高いほどプログラムの実行速度は速いです。
一方でコア数は、CPUの並列演算能力に寄与します。コアはCPUの動作する基本単位で、それが複数ある場合はマルチコアと呼ばれています。もともとはシングルコアのみしかありませんでしたが、シングルコアの場合は複数のプログラムを実行させるために、交互に動作させるプログラムを切り替えています。これをコンテキストスイッチと呼び、そのコストはとても高いです。スマートフォンに慣れている場合、動作しているアプリ(プロセス)は常に1つと思うかもしれませんが、実際にはOSなどさまざまなプロセスが並行して動作しています。そこでこのような状況でも最適な処理能力を提供するために、コアを複数積んだマルチコアが主流となりました。スマートフォン向けの場合、2022年現在2-8コア程度が主流です。
近年のマルチコア(とくにスマートフォン向け)は非対称コア(big.LITTLE)を搭載するCPUが主流となってきました。非対称コアとは、高性能コアと省電力コアを一緒に搭載しているようなCPUを指します。非対称コアのメリットは普段は省電力コアのみを動かして電池消費を節約し、ゲームなどパフォーマンスを出さないといけない時にコアを切り替えて使えるというところです。ただし省電力コアの分、並列性能の最大値は低下するので、コア数だけでは判断できないことに注意が必要です。
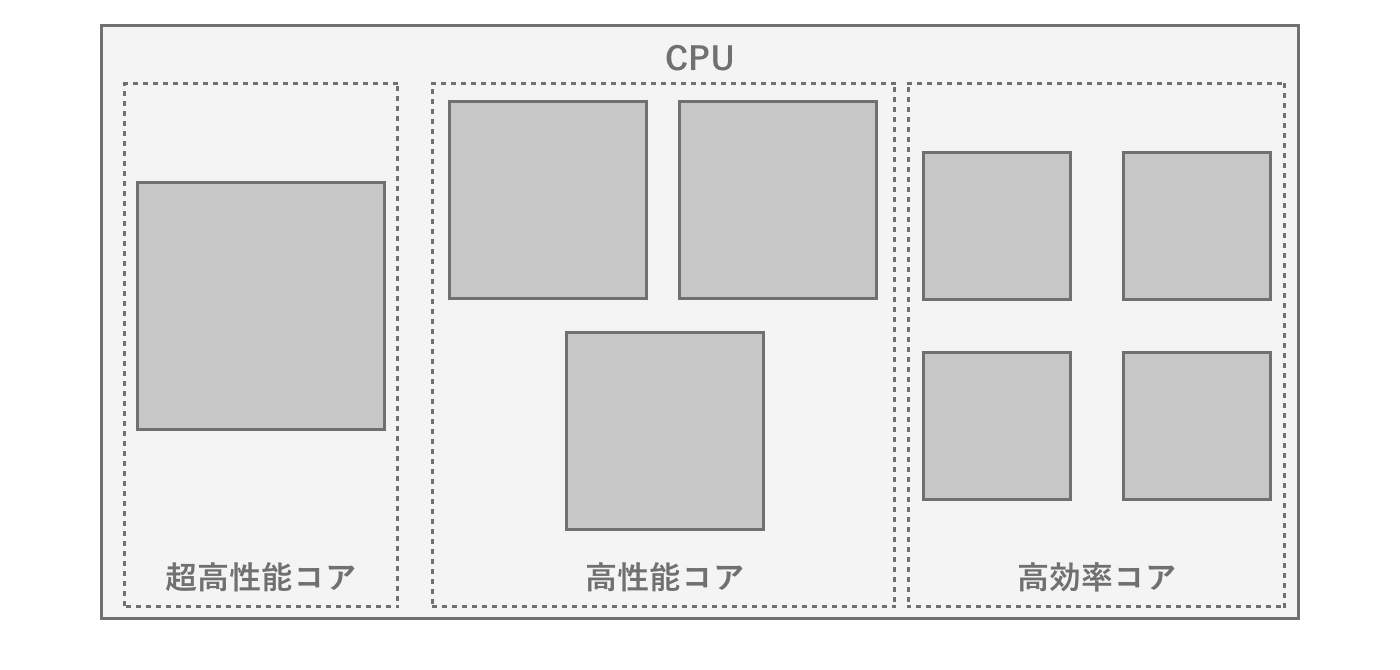
図2.4: Snapdragon 8 gen 1の異種コア構成
またプログラムが複数のコアを使い切れるかどうかは、プログラムの並列処理の記述に依存します。たとえばゲームエンジン側で物理エンジンを別スレッドで動作させるなどの効率化してあるケースや、UnityのJobSystemなどを通じて並列処理を活用しているケースもありますが、ゲームのメインループ自体の動作は並列化できないため、マルチコアであってもコア自体の性能は高いほうが有利です。
CPUのキャッシュメモリ
CPUとメインメモリは物理的に離れた場所に存在し、アクセスするためにほんの僅かな時間(レイテンシ)が必要になります。そのためプログラムを実行する際にメインメモリに格納されたデータにアクセスしようとすると、この距離が性能の大きなボトルネックとなります。そこでこのレイテンシの問題を解決するために、CPU内部にはキャッシュメモリが搭載されています。キャッシュメモリは、主にメインメモリに格納されているデータの一部を格納することで、プログラムが必要とするデータに素早くアクセスできるようにします。キャッシュメモリにはL1、L2、L3キャッシュがあり、数字が小さいほど高速ですが小容量です。どれぐらい小容量かというと、L3キャッシュでも2-4MBレベルです。そのためCPUキャッシュにはすべてのデータを保存することはできず、あくまで直近扱っているデータのみがキャッシュされます。
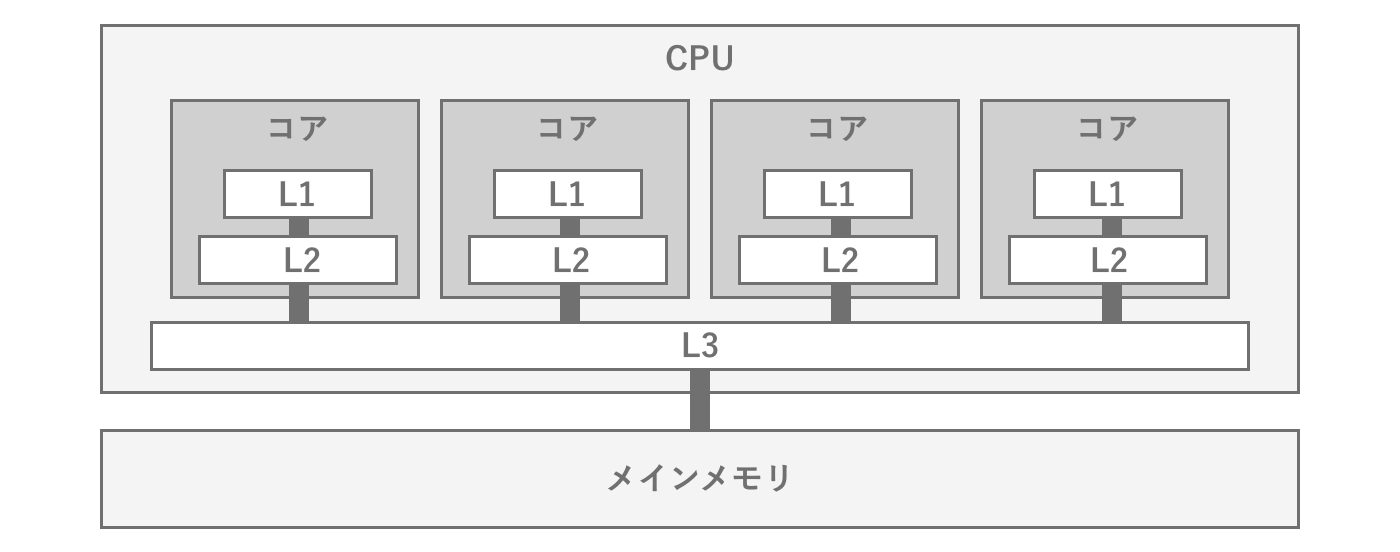
図2.5: CPUのL1、L2、L3キャッシュとメインメモリとの関係
そこでプログラムのパフォーマンスを高めるためには、データをいかにキャッシュに効率よく載せるかが鍵となりますが、プログラム側で自由にキャッシュを制御できないので、データの局所性が重要となります。ゲームエンジンにおいてはデータの局所性を意識したメモリ管理は難しいですが、UnityのJobSystemなど一部の仕組みではデータの局所性を高めたメモリ配置を実現できます。
2.1.4 GPU
CPUがプログラムを実行することに特化している一方で、GPU (Graphics Processing Unit)は画像処理やグラフィックスの描画に特化したハードウェアです。
GPUの基本
GPUはグラフィックス処理に特化させるため、CPUとは大きく構造が異なり、単純な計算を大量かつ並行して処理できるような設計となっています。たとえば1枚の画像を白黒にしたい場合、CPUを使って計算する場合はある座標のRGB値をメモリから読み取り、グレースケールに変換してメモリに戻す処理を画素毎に実行する必要があります。このような処理は分岐もなく、かつそれぞれの画素の計算は他の画素の結果に依存しないので、各画素における計算を並列で行うことが容易です。
そこでGPUでは大量のデータに対して同じ演算を適用するような並列処理が高速に実行でき、その結果グラフィックス処理が高速に実行できます。とくにグラフィックス系では浮動小数点の演算が大量に必要となるので、GPUは浮動小数点演算が得意です。そのため1秒間に何回浮動小数点の演算が行えるかというFLOPSと呼ばれる性能指標が一般的に用いられます。また演算能力だけではわかりづらいので、1秒間に何画素描画できるかというフィルレートと呼ばれる指標も用いられます。
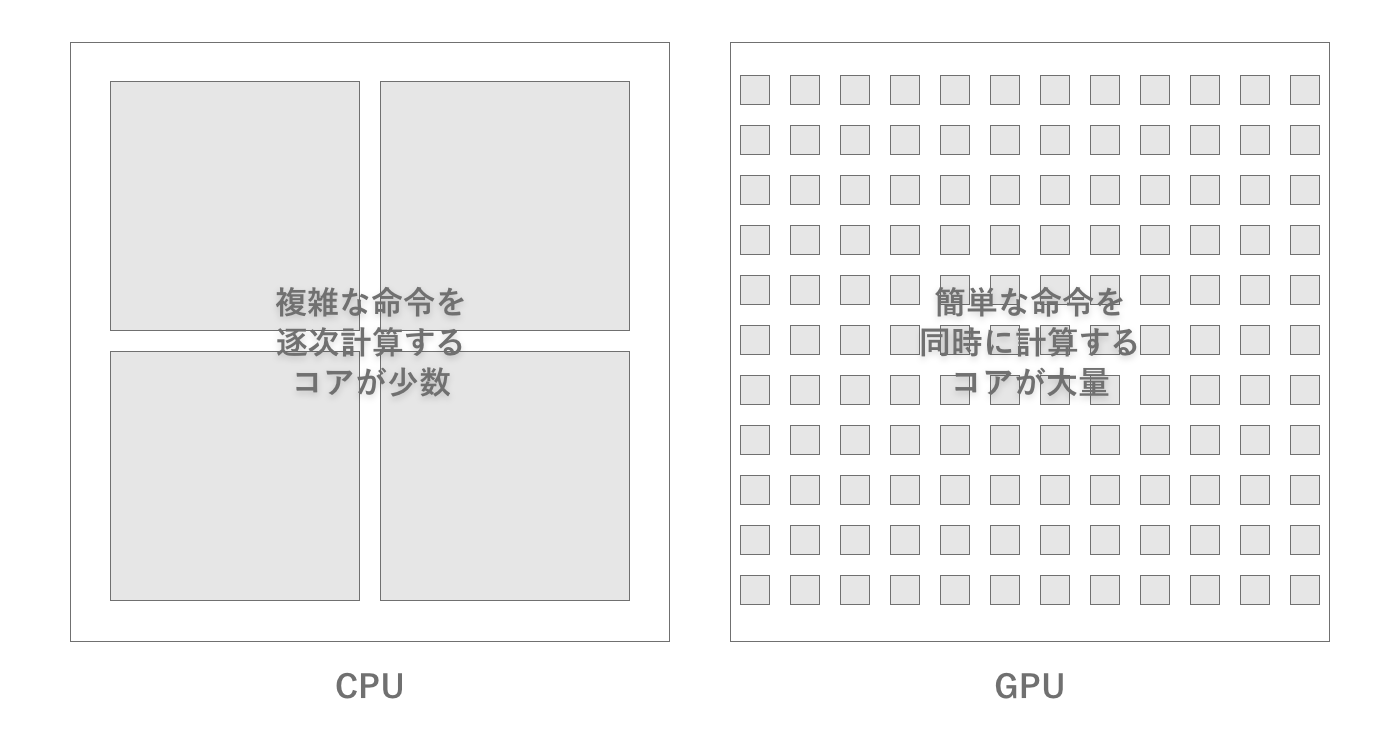
図2.6: CPUとGPUの違い
GPUの演算能力
GPUのハードウェアの特徴として、整数および浮動小数点の演算ユニットを含んだコアが大量(数十〜数千)に配置されているところにあります。コアを多く配置するために、CPUで必要だった複雑なプログラムを実行するのに必要なユニットは不要なので削ってあります。またCPUと同じように動作するクロック周波数が高ければ高いほど1秒間にたくさん演算できます。
GPUのメモリ
GPUももちろん、データを処理するために一時的に保存するためのメモリ領域を必要とします。通常、この領域はメインメモリと異なり、GPU専用のメモリとなります。そのため何かしらの処理を行うためには、メインメモリからGPUのメモリにデータを転送する必要があります。処理後には逆の手順でメインメモリに戻します。たとえば複数の解像度の大きいテクスチャの転送など転送量が大きい場合、転送に時間がかかり処理のボトルネックとなるため注意が必要です。
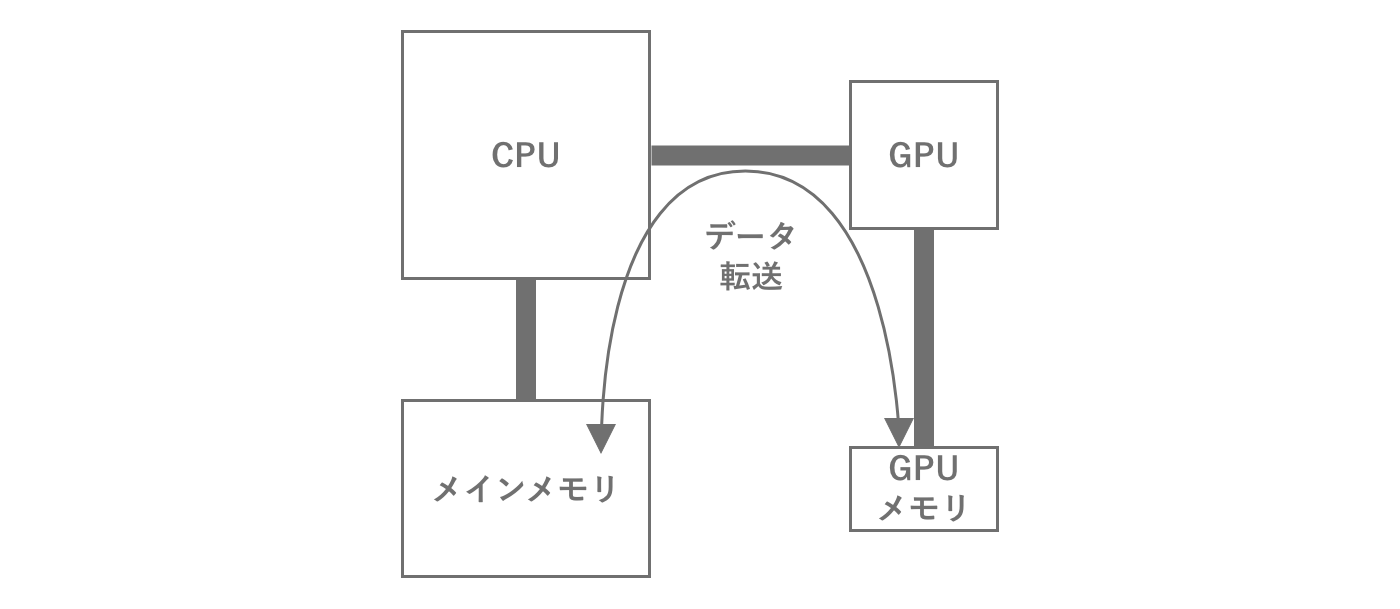
図2.7: GPUのメモリ転送
ただしモバイルにおいては、GPU専用のメモリを搭載するのではなく、メインメモリをCPUとGPUで共用するアーキテクチャが一般的です。これはGPUのメモリ容量を動的に変えることができるメリットがある一方で、転送帯域をCPUとGPUでシェアするというデメリットがあります。またこの場合においてもCPUとGPUのメモリ領域との間で、データの転送は必要です。
GPGPU
CPUでは不得意だった大量データに対する並列演算がGPUでは高速に実行できるため、近年はGPUをグラフィックス処理以外の目的にも適用する事例があり、GPGPU (General Purpose GPU)と呼ばれています。とくにAIなどの機械学習や、ブロックチェーンなどの計算処理に適用される事例が多くあり、そのためGPUの需要が急増し、価格高騰などの影響も出ています。またUnityにおいてもコンピュートシェーダーという機能を利用することで、GPGPUを利用できます。
2.1.5 メモリ
CPUはその時の計算に必要なデータのみを持つため、基本的にすべてのデータはメインメモリに保持されます。物理容量以上のメモリを使うことはできないため、使いすぎるとメモリを確保できなくなり、プロセスがOSから強制終了させられます。一般的にこれをOOM (Out Of Memory)でKillされたと呼びます。2022年現在のスマートフォンでは4-8GBのメモリ容量を備えた端末がメジャーですが、それでもメモリを使いすぎないように気をつける必要があります。
また前述のようにメモリがCPUと離れているため、メモリを意識した実装を行うかどうかでパフォーマンス自体も変わってきます。この節ではパフォーマンスを意識した実装が行えるように、プログラムとメモリの関係を解説します。
メモリ・ハードウェア
メインメモリがSoCの中にあったほうが物理的な距離上有利ではあるのですが、メモリはSoCには含まれていません。これはSoCの中に含まれているとメモリ搭載量を端末ごとに変えられないなどの理由があります。とは言えメインメモリが低速だとプログラムの実行速度に顕著に影響するので、比較的高速なバスでSoCとメモリを繋ぎます。このメモリとバスの規格でスマートフォンで一般的に使われているのがLPDDRという規格です。LPDDRにもいくつかの世代がありますが、理論上は数Gbps程度の転送速度です。もちろん常に理論性能を引き出せるわけではないですが、ゲーム開発ではここがボトルネックとなることはほぼないためそこまで意識する必要はありません。
メモリとOS
1つのOSの中ではたくさんのプロセスが同時に実行されていて、主にシステムプロセスとユーザープロセスがあります。システム系はOSを動作させるための重要な役割のプロセスが多く、サービスとして常駐しそのほとんどがユーザーの意思とは関係なく動き続けます。一方でユーザー系はユーザーの意思で起動したプロセスで、OSを動作させるためには必須ではありません。
スマートフォンでのアプリの表示状態としてフォアグラウンド(最前面)とバックグラウンド(非表示)状態があり、一般的には特定のアプリをフォアグラウンドにした場合は他のアプリはバックグラウンドになります。アプリがバックグラウンドにある間も復帰処理をスムーズにするためにプロセスは一時停止状態で存在し、メモリもそのまま維持されます。ところが全体で使用しているメモリが不足してきた場合は、OSで決められた優先順位にしたがってプロセスをKillします。この時にKillされやすいのが、メモリをたくさん使っているバックグラウンド状態のユーザー系アプリ(≒ゲーム)です。つまりメモリをたくさん使うゲームは、バックグラウンドに移った際にKillされる可能性が高くなり、その結果ゲームに戻ってきても起動からのやり直しとなるためユーザー体感が悪化します。
もしメモリを確保しようとした際、他に殺せるプロセスがなかった場合は自身がKillの対象となります。またiOSなどのように、物理容量の一定割合以上のメモリを1つのプロセスで使えないように制御されている場合もあります。そのためそもそもメモリを確保できる限界というのは存在します。2022年時点ではメジャーなRAMが3GBのiOS端末では、1.3~1.4GB程度が限界となりますので、ゲームを作る上ではこの辺りが上限となりやすいです。
メモリスワップ
現実にはさまざまなハードウェアの端末があり、搭載されているメモリの物理容量がとても小さいものもあります。OSはそのような端末でもなるべく多くのプロセスを動作させるために、さまざまな手法で仮想的なメモリ容量を確保しようとします。それがメモリスワップです。
メモリスワップで使われる1つの手法がメモリの圧縮です。しばらくアクセスのないメモリを中心に、圧縮してメモリ上に保管することで物理容量を節約します。ただし圧縮と展開コストがあるため、利用が活発な領域に対して行われず、たとえばバックグラウンドに行ったアプリに対して行われます。
もう1つの手法が不使用メモリのストレージ退避です。PCのようなストレージが潤沢なハードウェアではプロセスを終了してメモリを確保するのではなく、あまり使われていないメモリをストレージに退避させることで物理メモリの空きを確保しようとする場合があります。これはメモリ圧縮より大容量のメモリを確保できるというメリットがありますが、ストレージはメモリより低速なのでパフォーマンス上の制約が強いのと、そもそもストレージのサイズが小さいスマートフォンではあまり現実的ではないため採用されていません。
スタックとヒープ
スタックとヒープという言葉を一度は聞いたことがあるかもしれません。スタックは実はプログラムの動作に深く関係する専用の固定領域になります。関数が呼び出されるタイミングで引数やローカル変数などの分が確保され、元の関数へ戻る際に確保した分を解放し、戻り値を積み上げます。つまり関数の中で次の関数を呼び出す場合、現時点の関数の情報をそのままに、次の関数をメモリに積んでいきます。このようにすることで関数呼び出しの仕組みを実現しています。スタックメモリはアーキテクチャに依りますが1MBと容量自体がとても少ないので、限られたデータのみを格納します。
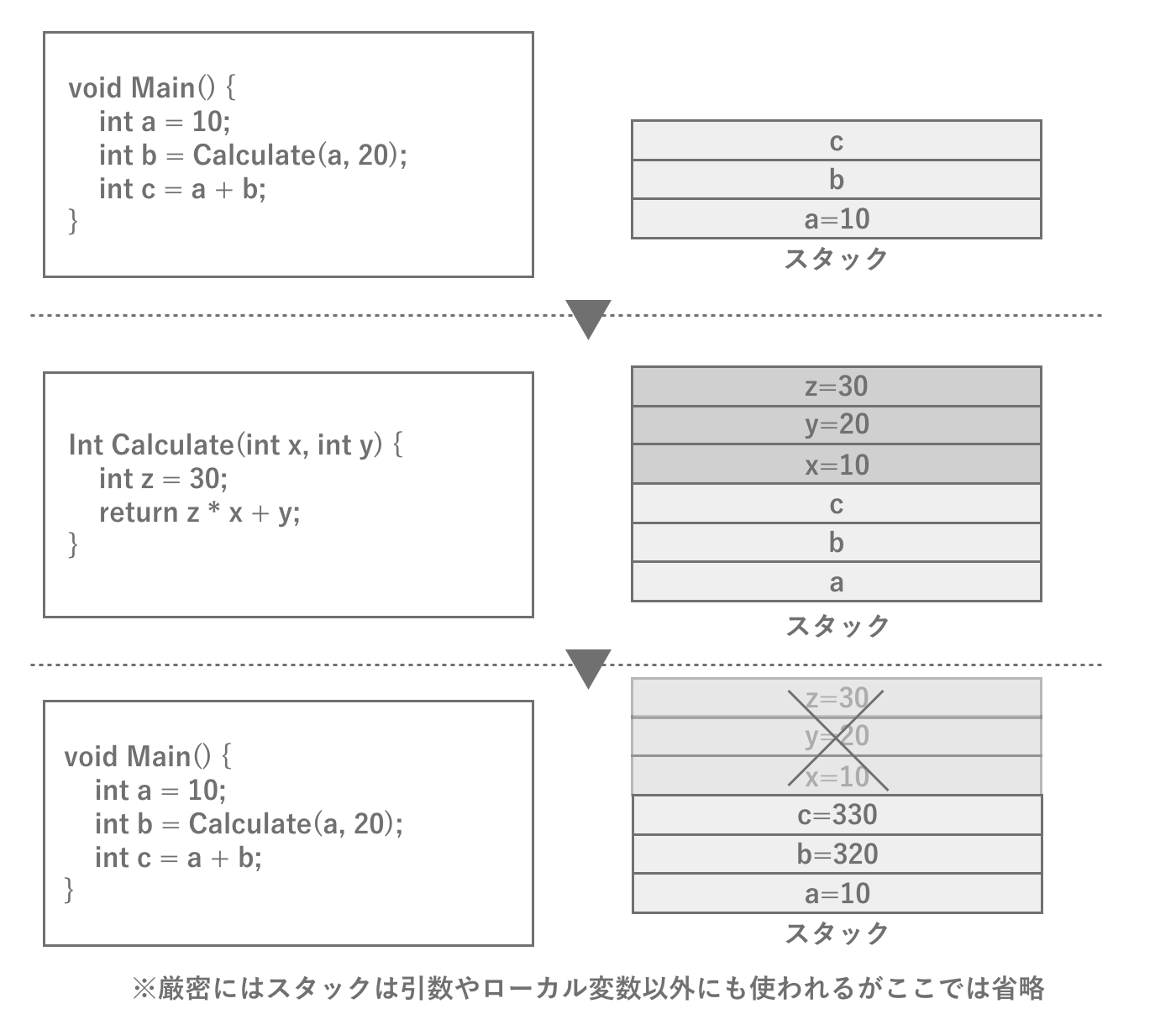
図2.8: スタックの動作模式図
一方でヒープはプログラム内部で自由に使えるメモリ領域になります。プログラムが必要とすればいつでもメモリ確保命令(Cではmalloc)を出し、大容量のデータを確保して使うことができます。もちろん使い終わったら解放処理(free)が必要です。C#ではメモリ確保と解放処理が自動的にランタイム側で行われるため、実装者が明示的に行うことはありません。
OS側はいつどれぐらいのメモリ容量が必要とされるかがわからないため、必要とされたタイミングでメモリの空き領域から確保して渡します。メモリ確保しようとした際に、連続してそのサイズを確保できない場合はメモリ不足となります。この連続というキーワードが重要です。一般的にメモリ確保と解放を繰り返すと、メモリの断片化が発生します。メモリが断片化すると、全体合計での空き領域が足りていても、連続で空いている領域がない場合が考えられます。このような場合、OSがまずはヒープの拡張を実行します。つまりプロセスに割り当てるメモリを新規に割り当てることで、連続領域を確保します。ただしシステム全体での有限なメモリのため、新規に割り当てるメモリがなくなった場合はOSからプロセスをKillされてしまいます。
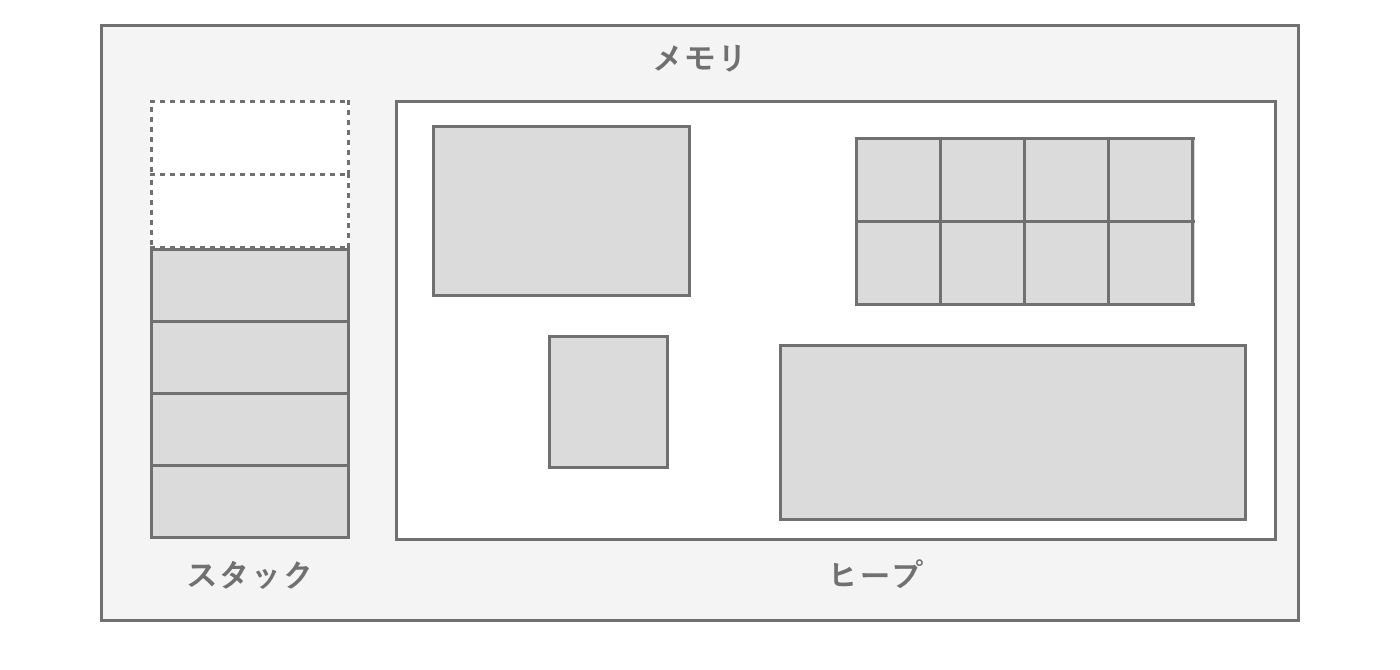
図2.9: スタックとヒープ
スタックとヒープを比較した際にはメモリ確保のパフォーマンスに顕著な差が生じます。それは関数に必要なスタックのメモリ量はコンパイル時点で確定するため、メモリ領域は確保済みなのに対し、ヒープは実行するまで必要なメモリ量がわからないため、都度空き領域から探して確保するからです。これがヒープが遅く、スタックは速いという所以です。
Stack Overflowエラー
Stack Overflowエラーは関数の再帰呼び出しなどでスタックメモリを使い切ったときに出てしまうエラーです。iOS/Androidのデフォルトのスタックサイズは1MBのため、再帰呼び出しによる探索規模が大きくなると発生しやすくなります。一般的には再帰呼び出しにならない、ないしは再帰呼び出しが深くならないアルゴリズムへの変更などで対策が可能です。
2.1.6 ストレージ
実際にチューニングを進めると、ファイルを読み込む場面で時間がかかっていることが多いことに気付くかもしれません。ファイルを読み込むということは、ファイルが保存されているストレージからデータを読み出して、プログラムから扱えるようにメモリに書き込んでいます。そこで実際に何が起きているかを知っておくとチューニングする時に便利です。
まず一般的なハードウェアアーキテクチャの場合は、データを永続化するために専用のストレージを持ちます。ストレージは大容量かつ電源なしでデータを永続化できる(不揮発)という特徴があります。この特徴を活かし、膨大なアセットはもちろんのこと、アプリ本体のプログラムなどもストレージに格納され、起動時などにストレージから読み込まれて実行されます。
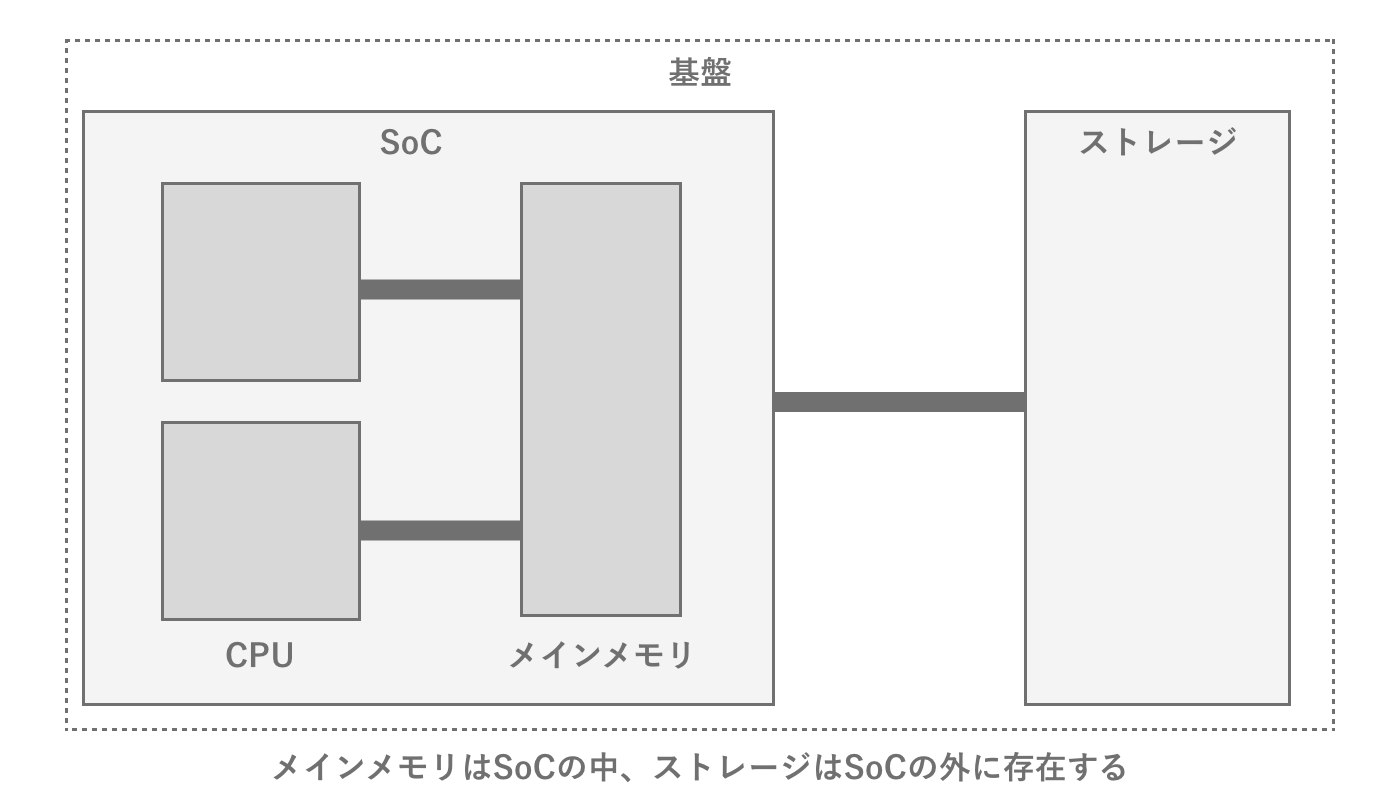
図2.10: SoCとストレージの関係性
RAMとROM
とくに日本ではスマホのメモリのことをRAM、ストレージのことをROMと書くことが主流となっていますが、実はROMはRead Only Memoryのことを指します。その名の通り読み取り専用で書き込みできないはずなのに、この用語が使われるのは日本の慣習が強いようです。
ところがこのストレージに対する読み書きの処理は、いくつかの観点からプログラムの実行周期と比較してとても遅いものとなっています。
- CPUとの物理的な距離がメモリと比べて離れているため、レイテンシが大きく読み書きの速度が遅い
- 命令されたデータとその周辺を含めてブロック単位で読み込むのでムダが多い
- シーケンシャルな読み書きは速い一方で、ランダムな読み書きは遅い
とくにこのランダムな読み書きが遅いというのは重要なポイントです。そもそもどういう場面でシーケンシャルになってどういう場面でランダムになるかと言えば、1つのファイルを先頭から順番に読み書きする場合はシーケンシャルになりますが、1つのファイルの複数箇所を飛び飛びに読み書きしたり、複数の小さなファイルを読み書きする場合はランダムになります。注意したいのは、同じディレクトリにある複数のファイルを読み書きする場合でも、物理的に連続して配置されているとは限らないため、物理的に離れている場合はランダムになります。
ストレージからの読み出し処理
ストレージからファイルを読み出す時に、細かい部分は省略しますが、ざっくり下記の流れで処理されます。
- プログラムがストレージから読み込みたいファイルの領域をストレージコントローラーに命令する
- ストレージコントローラーが命令を受け取り、データのある物理上の読み込む領域を計算する
- データを読み込む
- データをメモリ上に書き込む
- プログラムがメモリを通してデータにアクセスする
またハードウェアやアーキテクチャによってはコントローラーなどのレイヤーが増えたりもします。正確に覚えておく必要はないですが、メモリからの読み出しと比較してハードウェアの処理工程が多いというのは意識しましょう。
また一般的なストレージは1つのファイルを4KBなどのブロック単位に書き込むことで、パフォーマンスと空間効率を達成しています。このブロックは1つのファイルだとしても物理的に連続して配置されるとは限りません。ファイルが物理的に分散している状態を断片化 (フラグメンテーション)と呼び、断片化を解消する操作をデフラグと呼びます。PCで主流だったHDDでは断片化が問題となることが多かったのですが、フラッシュストレージになり影響はほぼなくなりました。スマホにおいてはファイルの断片化を意識する必要はありませんが、PCを考慮する場合は気をつける必要があります。
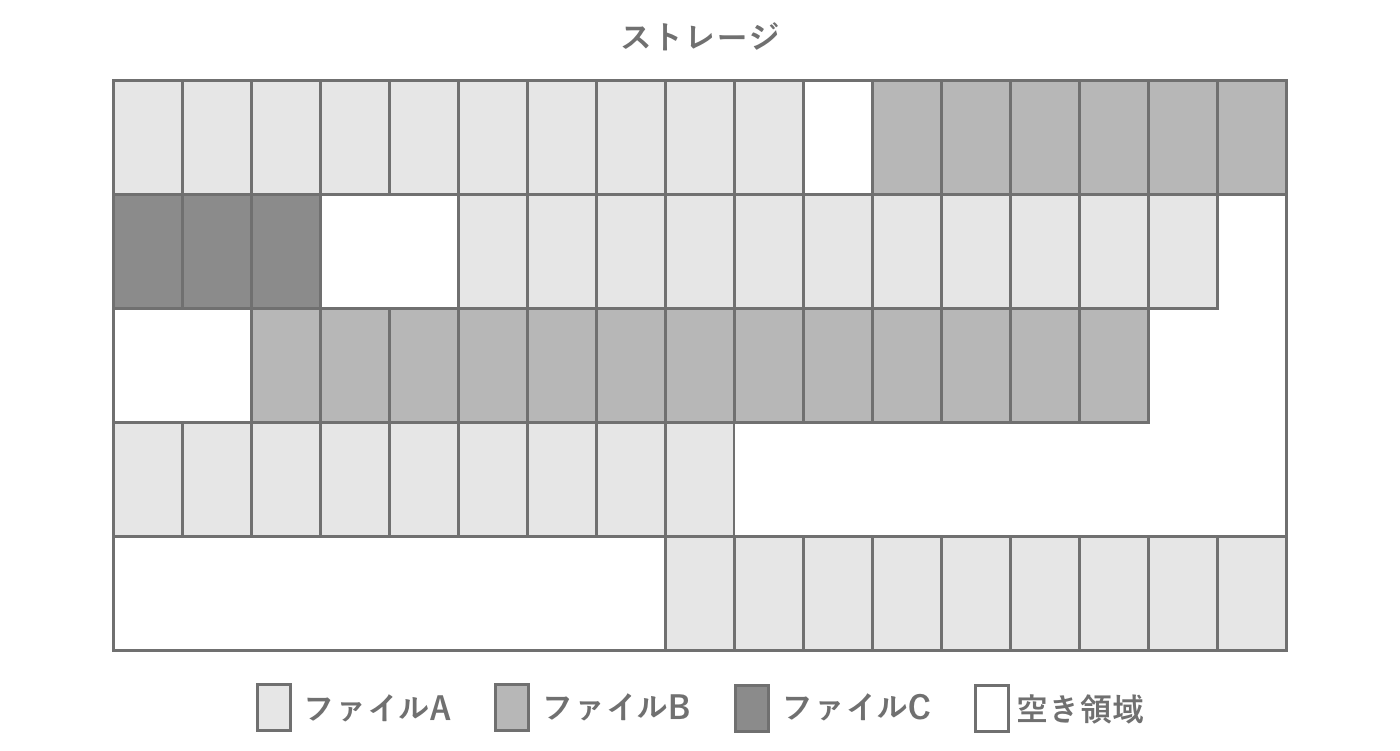
図2.11: ストレージの断片化
PCとスマホにおけるストレージの種類
PCの世界ではHDDとSSDが主流です。HDDを見たことないという人もいるかもしれませんが、CDのように円盤状に記録されるメディアで、ディスクの上をヘッドが動いて磁気を読み取ります。そのため構造的にも大きく、また物理的な動きが発生するためレイテンシが大きい装置でした。近年はSSDが普及し、これはHDDと異なり物理的な動きが発生しないため高速な性能を発揮しますが、その一方で読み書き回数の限界(寿命)があるため頻繁に読み書きが発生すると使えなくなるという特徴があります。スマホはSSDとは違いますが、NANDと呼ばれるフラッシュメモリの一種が使われています。
最後に、実際にスマホにおいてストレージがどれぐらいの読み書きの速度があるかですが、2022年現在の1つの目安としては読み込みで100MB/s程度となります。仮に10MBのファイルを読み取りたい場合では、理想的な状況であってもファイル全体を読み取るために100ms必要となります。さらに複数の細かいファイルを読み込む場合はランダムアクセスが発生するので、ますます読み取りに時間がかかるようになります。このように実は意外とファイルの読み込みに時間がかかるというのは常に意識しておいた方がよいです。個別の端末の具体的な性能に関してはベンチマーク結果を集めたサイト*1があるので参考にしましょう。
最後にまとめると、ファイルの読み書きが発生する場合は以下の観点を意識するとよいです。
- ストレージの読み書き速度は意外と遅く、メモリと同等の速度を期待しない
- 同時に読み書きするファイルの数はできる限り減らす(タイミングを分散させる、1つのファイルに纏めるなど)
2.2 レンダリング
ゲームにおいてレンダリングの処理負荷はしばしばパフォーマンスに悪影響を及ぼします。したがって、レンダリングに関する知識はパフォーマンスチューニングを行う上で必須であるといえます。そのためこの節では、レンダリングの基礎知識についてまとめます。
2.2.1 レンダリングパイプライン
コンピュータグラフィックスでは、3Dモデルの頂点座標やライトの座標と色などのデータに対して一連の処理を行なうことで、最終的に画面上の各画素に出力する色を出力します。この処理の仕組みをレンダリングパイプラインと呼びます。
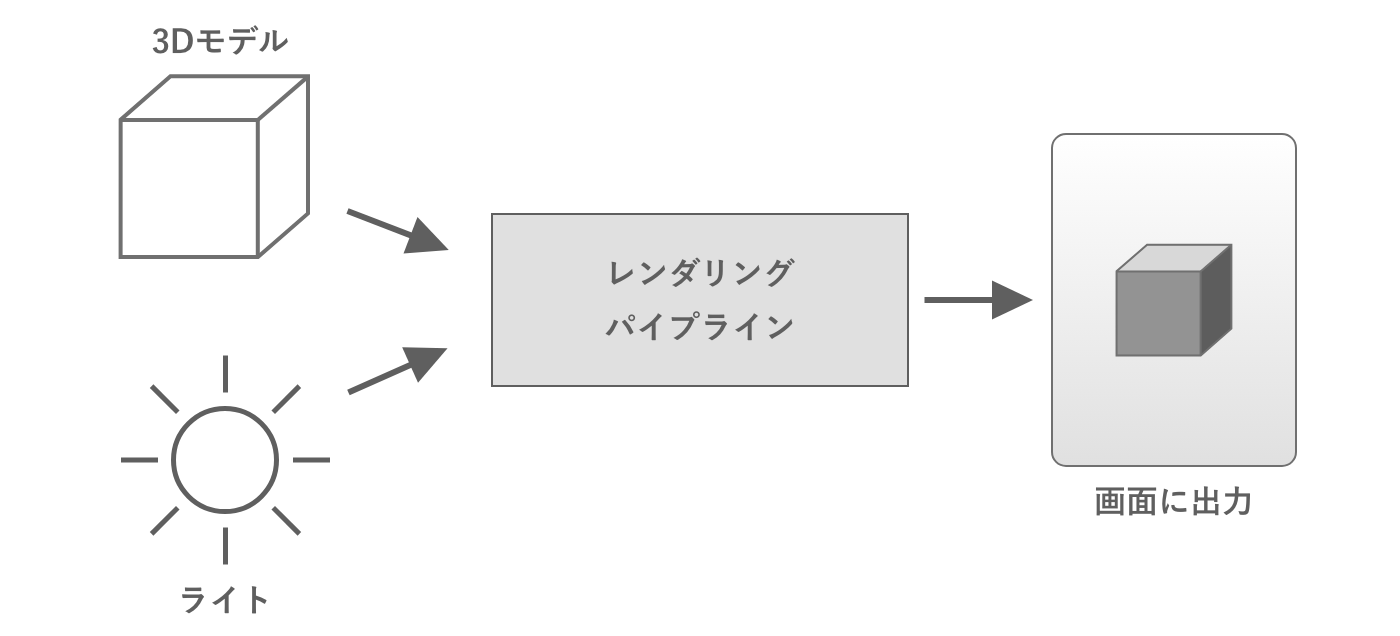
図2.12: レンダリングパイプライン
レンダリングパイプラインは、CPUからGPUに必要なデータを送るところから始まります。描画するべき3Dモデルの頂点座標やライトの座標をはじめとして、オブジェクトの材質の情報やカメラの情報などさまざまなデータが送られます。
このとき送られてくるのは、3Dモデルの頂点座標やカメラの座標、向き、画角などそれぞれ個別のデータです。GPUはこれらの情報をまとめて「そのカメラでそのオブジェクトを映した場合に、画面上のどの位置にオブジェクトが表示されるか」を計算して求めます。この処理を座標変換と呼びます。
オブジェクトが画面上のどの位置に表示されるかが決まったら、次にオブジェクトの色を求める必要があります。そこで今度はGPUは「そのライトでその材質のモデルを照らしたときに、画面上の各画素に対応する部分はどのような色になるか」を計算して求めます。
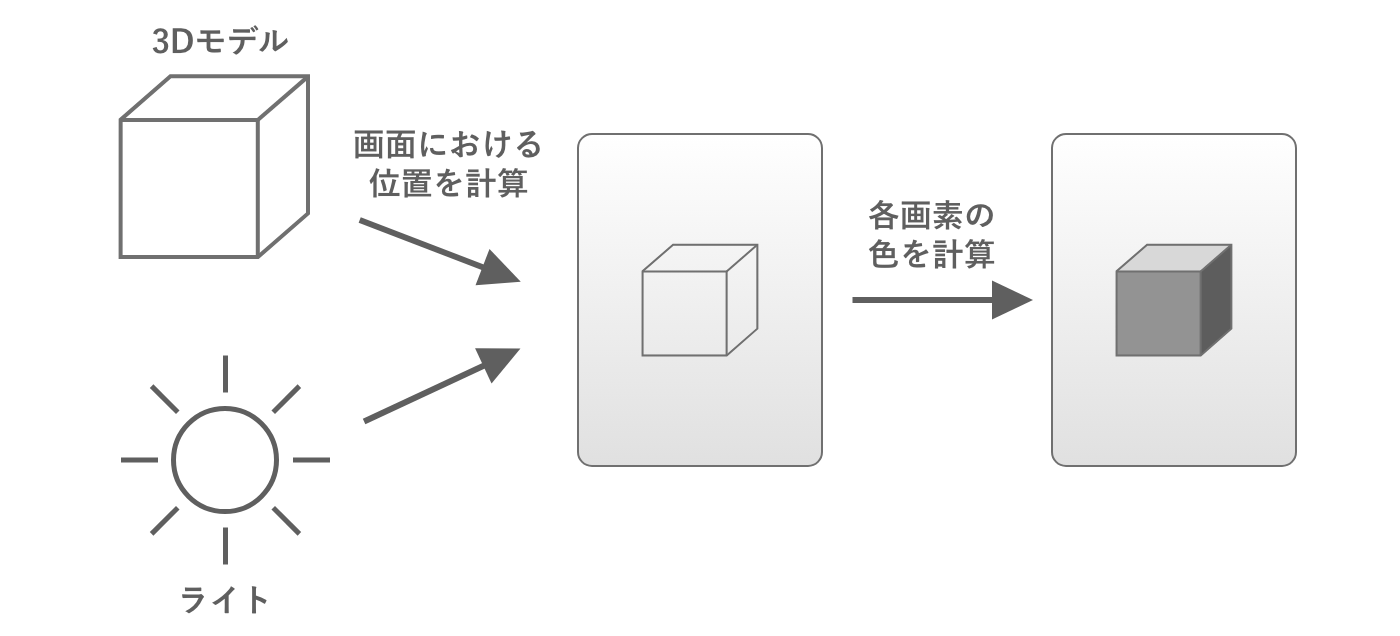
図2.13: 位置と色を計算
上述の処理のうち、「画面上のどの位置にオブジェクトが表示されるか」は頂点シェーダーと呼ばれるプログラムにより計算され、「画面上の各画素に対応する部分はどのような色になるか」はフラグメントシェーダーと呼ばれるプログラムにより計算されます。
そしてこれらのシェーダーは自由に記述できます。したがって、頂点シェーダーやフラグメントシェーダーに重い処理を書いてしまうと処理負荷が増大します。
また、頂点シェーダーの処理は3Dモデルの頂点の数だけ処理されるため、頂点の数が多いほど処理負荷が大きくなります。フラグメントシェーダーはレンダリング対象の画素数が多いほど処理負荷が大きくなります。
実際のレンダリングパイプライン
実際のレンダリングパイプラインでは頂点シェーダーやフラグメントシェーダー以外にも多くのプロセスが存在しますが、本書ではパフォーマンスチューニングに必要な概念の理解を目的としているため、簡易的な説明に留めます。
2.2.2 半透明描画とオーバードロー
レンダリングを行うにあたり、対象のオブジェクトの透明度は重要な問題です。たとえばいま、カメラから見たときに一部分が重なっている2つのオブジェクトについて考えます。
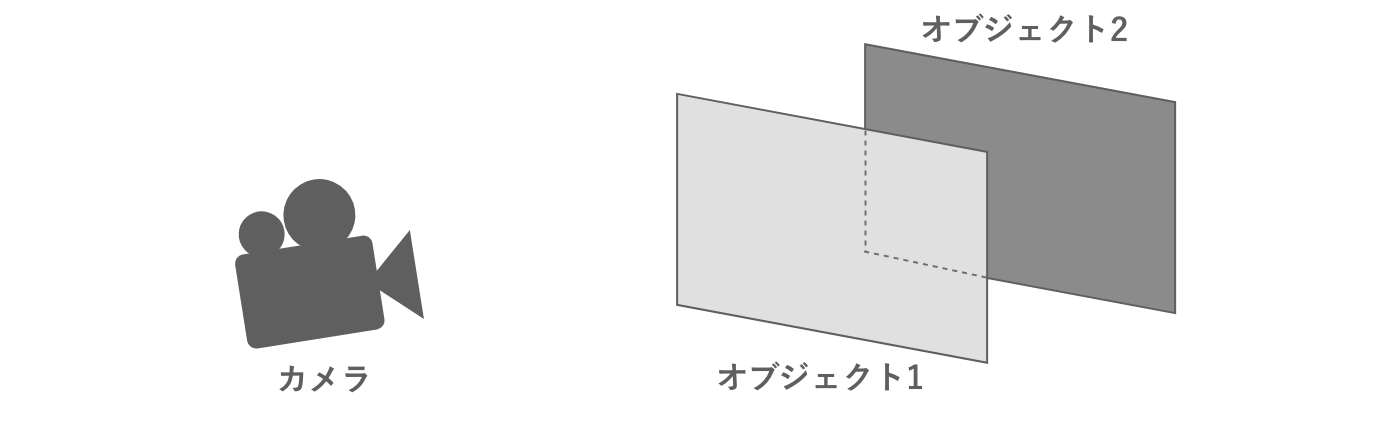
図2.14: 重なっている2つのオブジェクト
まずこれらのオブジェクトが両方とも不透明であるケースを考えます。この場合、カメラから見て手前にあるオブジェクトから順番に描画処理が行われます。こうすると、奥側のオブジェクトを描画する際に、手前のオブジェクトに重なって見えていない部分は処理する必要がありません。つまりこの部分はフラグメントシェーダーの演算をスキップできるということになり、結果として処理負荷を最適化できます。
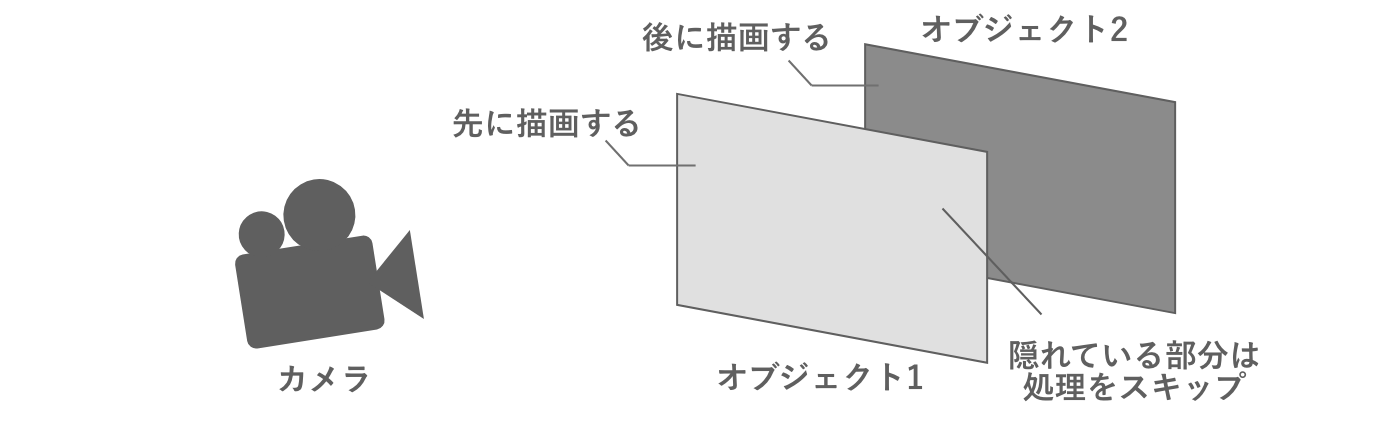
図2.15: 不透明描画
一方、両方のオブジェクトが半透明だった場合には、手前のオブジェクトに重なっている部分であっても奥側のオブジェクトが透けて見えていなければ不自然です。この場合には、カメラから見て奥側にあるオブジェクトから順番に描画処理を行い、重なった部分の色はすでに描画されている色とブレンドします。
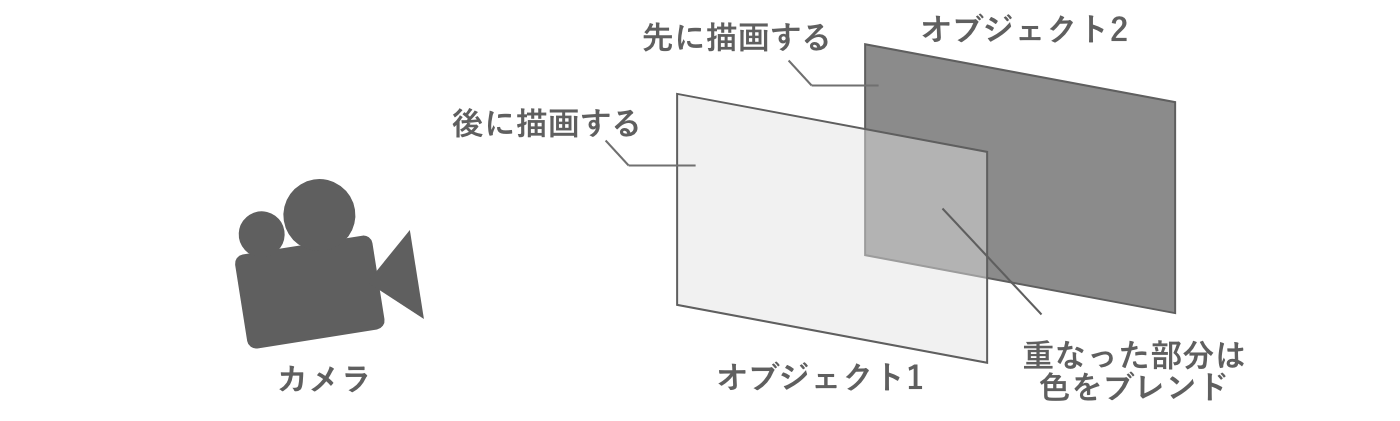
図2.16: 半透明描画
このように、半透明描画は不透明描画と異なり、オブジェクト同士が重なっている部分についても描画処理を行う必要があります。もし画面いっぱいに描画される半透明なオブジェクトが2つ存在していたら、画面いっぱい分の処理が2回行われるということになります。このように、半透明なオブジェクトを重ねて描画することをオーバードローと呼びます。オーバードローが多すぎるとGPUに大きな処理負荷がかかり、パフォーマンスの低下に繋がるため、半透明描画を行う際には適切にレギュレーションを設ける必要があります。
フォワードレンダリングを想定
レンダリングパイプラインにはいくつかの実装方法があります。そのうち、本項の記述はフォワードレンダリングを想定しています。デファードレンダリングなど他のレンダリング手法には部分的に当てはまらない点もあります。
2.2.3 ドローコール・セットパスコールとバッチング
レンダリングの際にはGPUだけではなくCPUにも処理負荷がかかります。
上述の通り、オブジェクトをレンダリングする際にはCPUからGPUに描画するための命令を出します。これはドローコールと呼ばれ、レンダリングするオブジェクトの数だけ実行されます。またこのときに、テクスチャなどの情報が前回のドローコールで描画したオブジェクトのものと異なっている場合には、それらをGPUに設定する処理を行います。これはセットパスコールと呼ばれ、比較的重い処理になります。この処理はCPUのレンダースレッドで行われるため、CPUに処理負荷がかかり、多すぎるとパフォーマンスに影響を及ぼします。
Unityには、ドローコールを削減するためにドローコールバッチングと呼ばれる仕組みが実装されています。これは同じテクスチャなどの情報、つまり同じマテリアルを持つオブジェクトのメッシュをあらかじめCPU側の処理で結合してしまい、1回のドローコールで描画する仕組みです。ランタイムでバッチングするダイナミックバッチングと、あらかじめ結合したメッシュを作成しておくスタティックバッチングがあります。
また、Scriptable Render PipelineにはSRP Batcherという仕組みが実装されています。これを使うと、シェーダーバリアントが同一であれば、メッシュやマテリアルが違っていたとしてもセットパスコールを1回にまとめることができます。ドローコールは減りませんが、大きな処理負荷がかかるのはセットパスコールであるため、こちらを減らすための仕組みです。
これらのバッチングについてのより詳細な情報は「7.3 ドローコールの削減」を参照してください。
GPUインスタンシング
バッチングに似た効果を得られる機能として、GPUインスタンシングがあります。これはGPUの機能を使うことで、同じメッシュを持つオブジェクトを一度のドローコール・セットパスコールで描画できる機能です。
2.3 データの表現方法
ゲームには画像や3Dモデル、音声、アニメーションなどさまざまなデータが使われます。これらがデジタルデータとしてどのように表現されているかを知ることは、メモリやストレージの容量を計算したり、圧縮などの設定を適切に行ったりする上で重要です。この節では基本的なデータの表現方法についてまとめます。
2.3.1 ビットとバイト
コンピューターが表現できる最小の単位はビットです。1ビットでは2進数の1桁で表せる範囲、つまり0か1の2通りの組み合わせを表現できます。これではたとえばスイッチのON・OFFなどといった簡単な情報しか表せません。

図2.17: 1ビットの情報量
ここでビットを2つ使うと、2進数の2桁で表せる範囲、つまり4通りの組み合わせを表現できることがわかります。4通りなのでたとえば上・下・左・右のどのキーが押されたかといった情報を表せそうです。

図2.18: 2ビットの情報量
同様に8ビットになると2進数の8桁で表せる範囲、つまり2通り ^ 8桁 = 256通りです。ここまでくると色々な情報が表現できそうです。そしてこの8ビットは1バイトという単位で表されます。つまり1バイトとは256通りの情報量を表せる単位であるということができます。
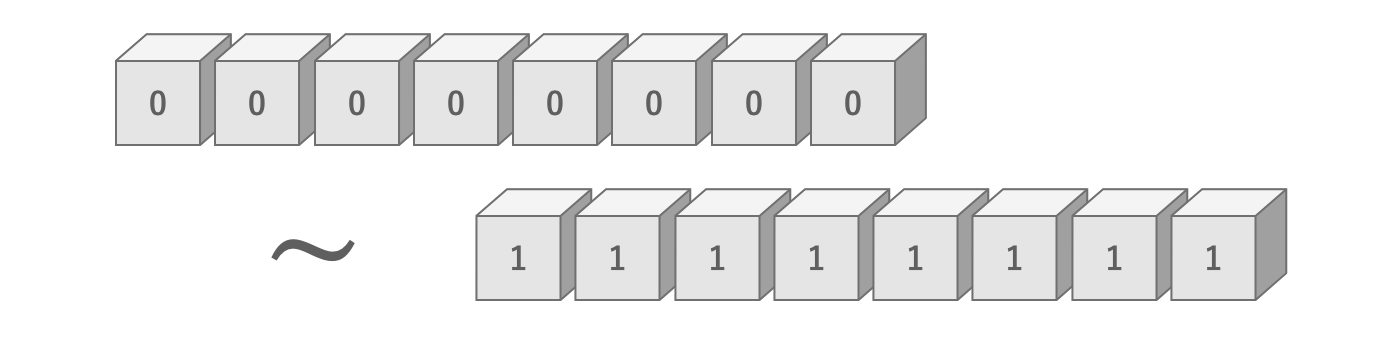
図2.19: 8ビットの情報量
また、さらに大きな数を表す単位として、1000バイトを表す1キロバイト (KB)や、1000キロバイトを表す1メガバイト (MB)が存在します。
キロバイトとキビバイト
上記では1KBを1,000バイトと書きましたが、文脈によっては1KBを1,024バイトとする場合もあります。明示的に呼び分ける場合には、1000バイトを1キロバイト (KB)と呼び、1,024バイトを1キビバイト (KiB)と呼びます。メガバイトについても同様です。
2.3.2 画像
画像データはピクセルの集合として表されています。たとえば8 × 8ピクセルの画像であれば、合計8 × 8 = 64個のピクセルで構成されています。
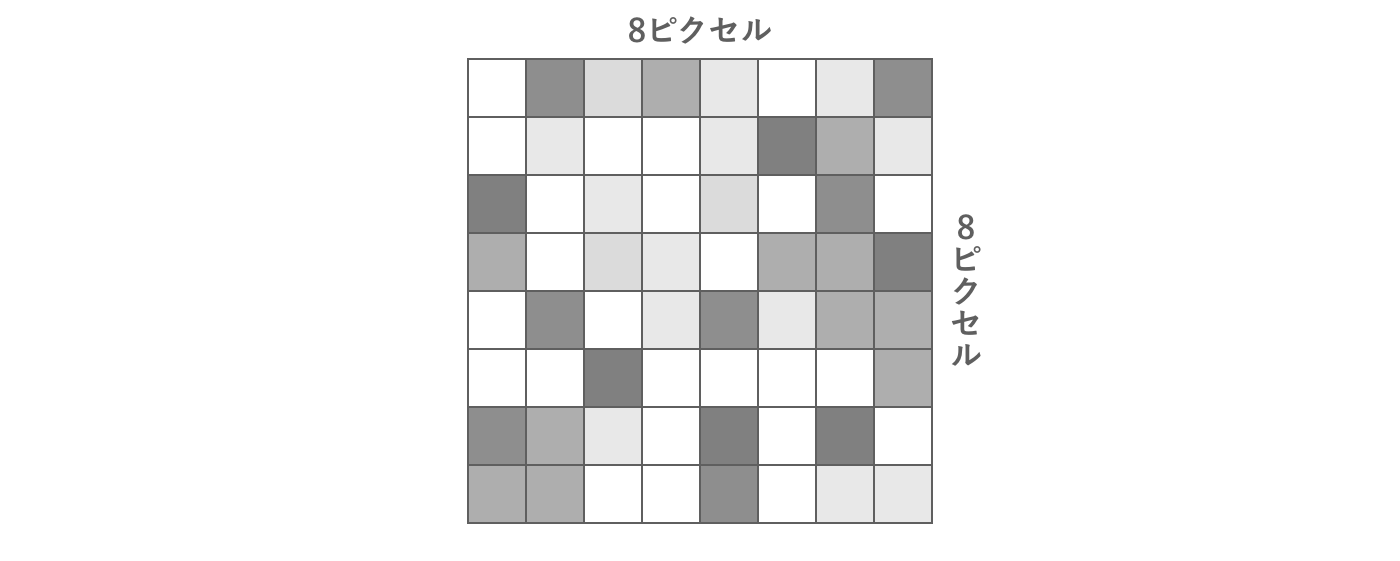
図2.20: 画像データ
このとき、各ピクセルはそれぞれ色のデータを持っています。では色はデジタルデータでどのように表現されるのでしょうか。
まず色は赤 (Red)、緑 (Green)、青 (Blue)、透明度 (Alpha)の4つの要素を組み合わせて作られます。これらをチャンネルと呼び、それぞれのチャンネルの頭文字をとってRGBAと表現します。
よく使われるTrue Colorという色の表現方法では、RGBAの各値をそれぞれ256段階で表します。前節で説明した通り、256段階とはつまり8ビットです。すなわちTrue Colorは4チャンネル × 8ビット = 32ビットの情報量で表すことができます。
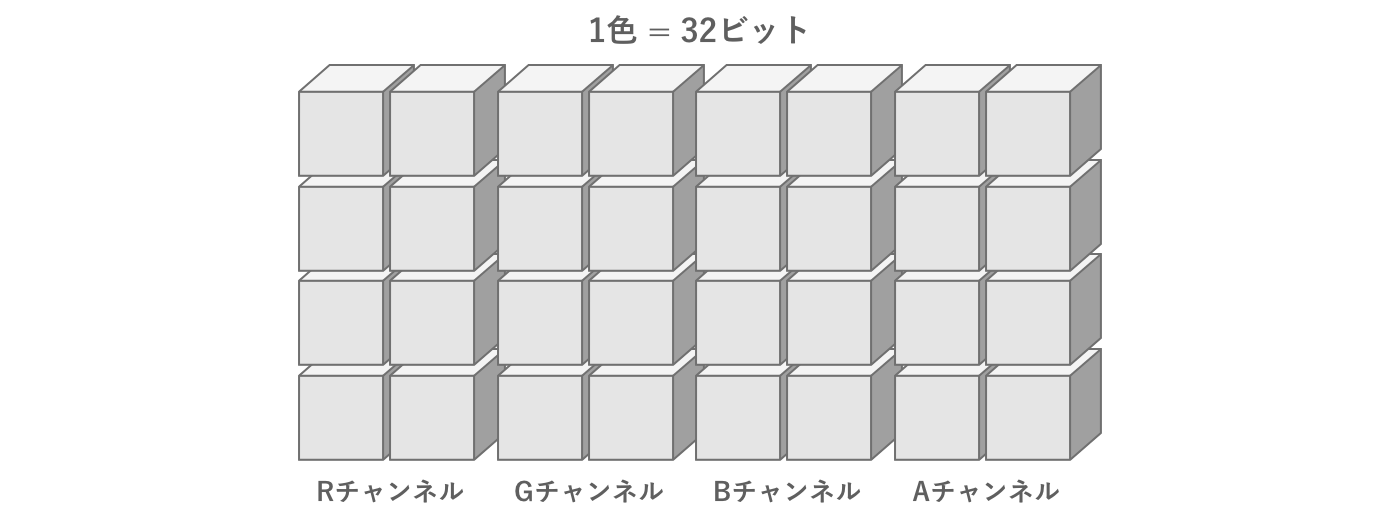
図2.21: 1色の情報量
したがって、たとえば8 × 8ピクセルのTrue Colorの画像であればその情報量は8ピクセル × 8ピクセル × 4チャンネル × 8ビット = 2,048ビット = 256バイトとなります。1,024 × 1,024ピクセルのTrue Colorの画像であれば、その情報量は1,024ピクセル × 1,024ピクセル × 4チャンネル × 8ビット = 33,554,432ビット = 4,194,304バイト = 4,096キロバイト = 4メガバイトとなります。
2.3.3 画像の圧縮
実際には、画像は圧縮されたデータとして使用されることがほとんどです。
圧縮とは、データの格納方法を工夫することでデータ量を減らすことです。たとえばいま、同じ色をしたピクセルが5つ隣り合っていたとします。この場合、各ピクセルの色情報を5つ持つよりも、色の情報ひとつと、それが5個並んでいるという情報を持った方が情報量は減ります。

図2.22: 圧縮
実際にはもっと複雑な圧縮方法がたくさん存在します。
具体例として、モバイルで代表的な圧縮フォーマットであるASTCを紹介します。ASTC6x6というフォーマットを適用すると、1024x1024のテクスチャが4メガバイトから約0.46メガバイトに圧縮されます。つまり、容量は8分の1以下に圧縮されたという結果となり、圧縮を行うことの重要性を認識できます。
参考までに、モバイルで主に利用されるASTCフォーマットの圧縮率について以下に記載します。
表2.2: 圧縮形式と圧縮率
| 圧縮形式 | 圧縮率 |
|---|---|
| ASTC RGB(A) 4x4 | 0.25 |
| ASTC RGB(A) 6x6 | 0.1113 |
| ASTC RGB(A) 8x8 | 0.0625 |
| ASTC RGB(A) 10x10 | 0.04 |
| ASTC RGB(A) 12x12 | 0.0278 |
なおUnityでは、テクスチャのインポート設定によりさまざまな圧縮方法を、プラットフォームごとに指定できます。そのため非圧縮の画像をインポートし、このインポート設定により圧縮をかけることで最終的に使用されるテクスチャを生成するというやり方が一般的となっています。
GPUと圧縮形式
あるルールに基づいて圧縮した画像は、当然ですがそのルールに基づいて展開する必要があります。この展開処理はランタイムで行われます。この処理負荷を最小限に抑えるため、GPUが対応した圧縮形式を使うことが重要です。モバイルデバイスのGPUが対応している代表的な圧縮形式としてASTCが挙げられます。
2.3.4 メッシュ
3DCGでは、3D空間上に三角形を多数繋ぎ合わせることで立体形状を表現しています。この三角形の集まりをメッシュと呼びます。
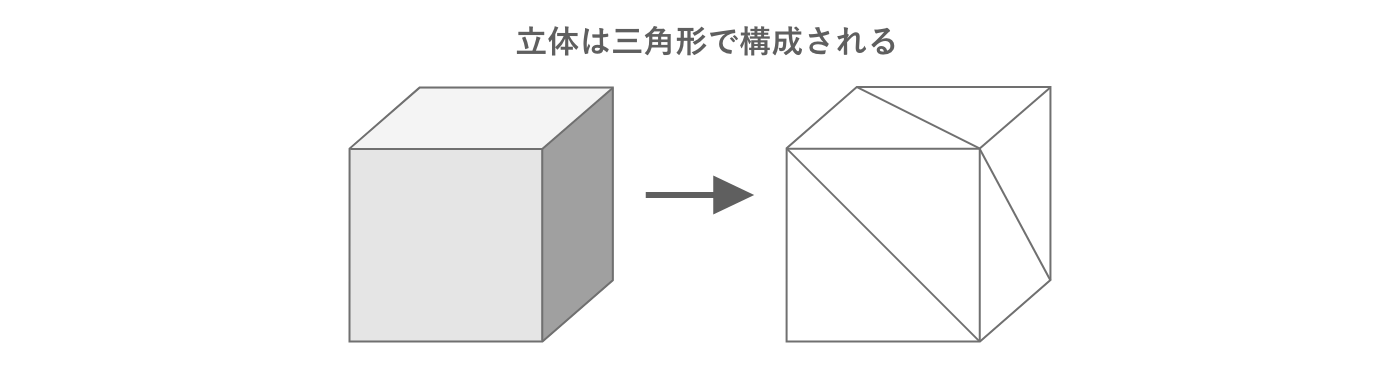
図2.23: 三角形の組み合わせによる立体
この三角形は、データとしては3D空間上の3点の座標情報として表すことができます。この各点を頂点と呼び、その座標を頂点座標と呼びます。またメッシュ1つあたりの頂点情報はすべて1つの配列に格納されます。
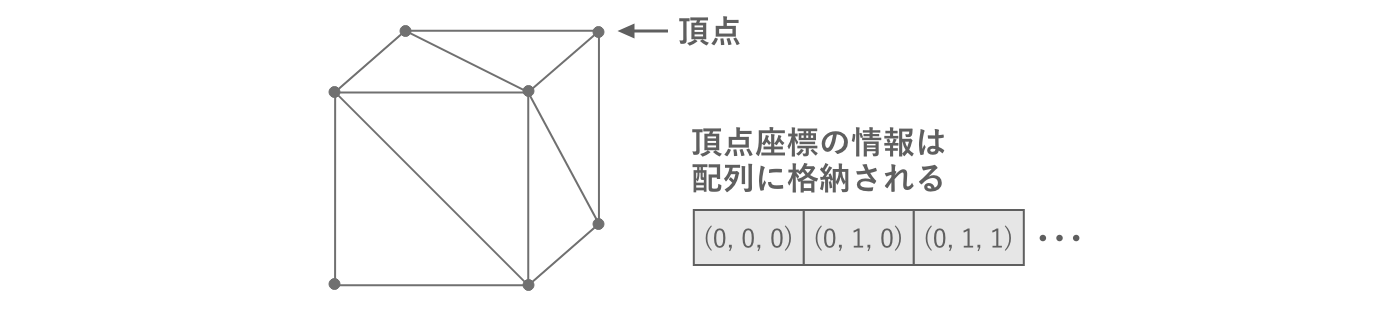
図2.24: 頂点情報
頂点情報は1つの配列に格納されるため、そのうちのどれを組み合わせて三角形を構成するかを表す情報が別途必要です。これを頂点インデックスと呼び、頂点情報の配列のインデックスを表すint型の配列として表現されます。
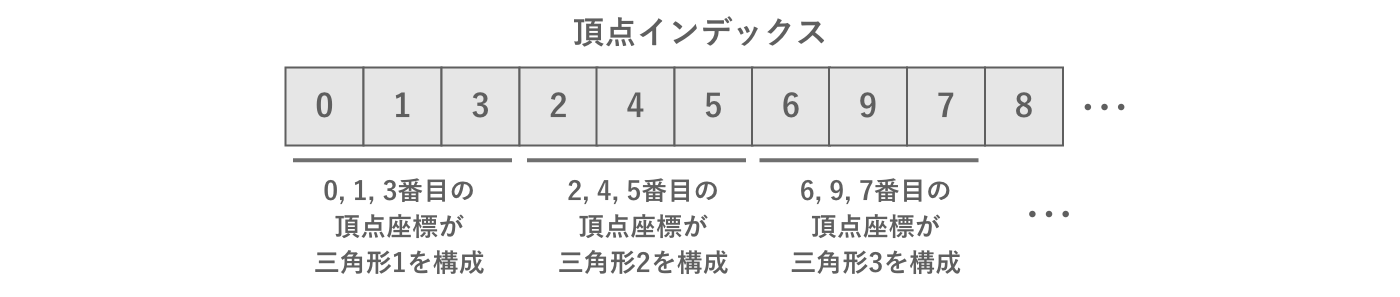
図2.25: 頂点インデックス
オブジェクトにテクスチャを貼り付けたり、ライティングを行なったりする上ではさらに追加の情報が必要です。たとえばテクスチャをマッピングするにはUV座標が必要です。またライティングをする上では、頂点カラーや法線、接線などの情報も使われます。
次の表は、主な頂点情報と1頂点あたりの情報量をまとめたものです。
表2.3: 頂点情報
| 名前 | 1頂点あたりの情報量 |
|---|---|
| 頂点座標 | 3次元のfloat = 12バイト |
| UV座標 | 2次元のfloat = 8バイト |
| 頂点カラー | 4次元のfloat = 16バイト |
| 法線 | 3次元のfloat = 12バイト |
| 接線 | 3次元のfloat = 12バイト |
メッシュのデータは頂点の数や1つの頂点で扱う情報の量が増えるほど大きくなるため、頂点数や頂点情報の種類を事前に決めておくことは重要です。
2.3.5 キーフレームアニメーション
ゲームではUIのアニメーションや3Dモデルのモーションなど、多くの箇所にアニメーションを使用します。アニメーションの代表的な実現手法として、キーフレームアニメーションがあります。
キーフレームアニメーションは、ある時間(キーフレーム)における値を表すデータの配列で構成されます。キーフレーム間の値は補間により求められるので、あたかも滑らかに連続したデータであるかのように取り扱うことができます。
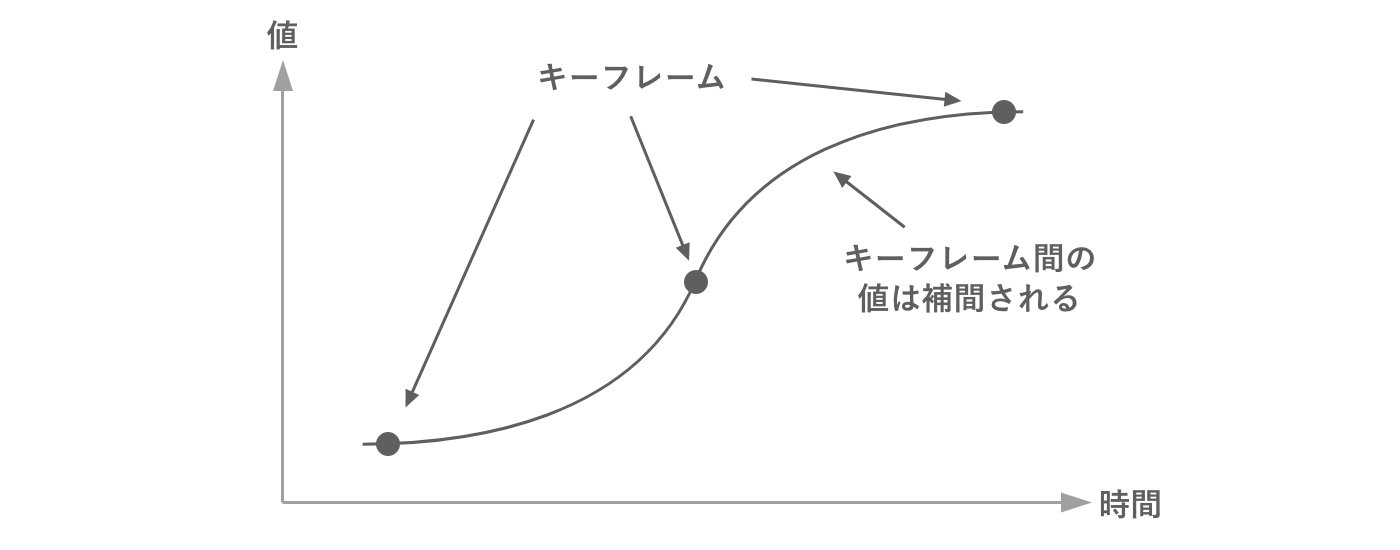
図2.26: キーフレーム
なおキーフレームが持つ情報は時間と値の他に、接線やその重みといったものがあります。これらを補間の計算に利用することで、少ないデータ量でより複雑なアニメーションを実現することできます。
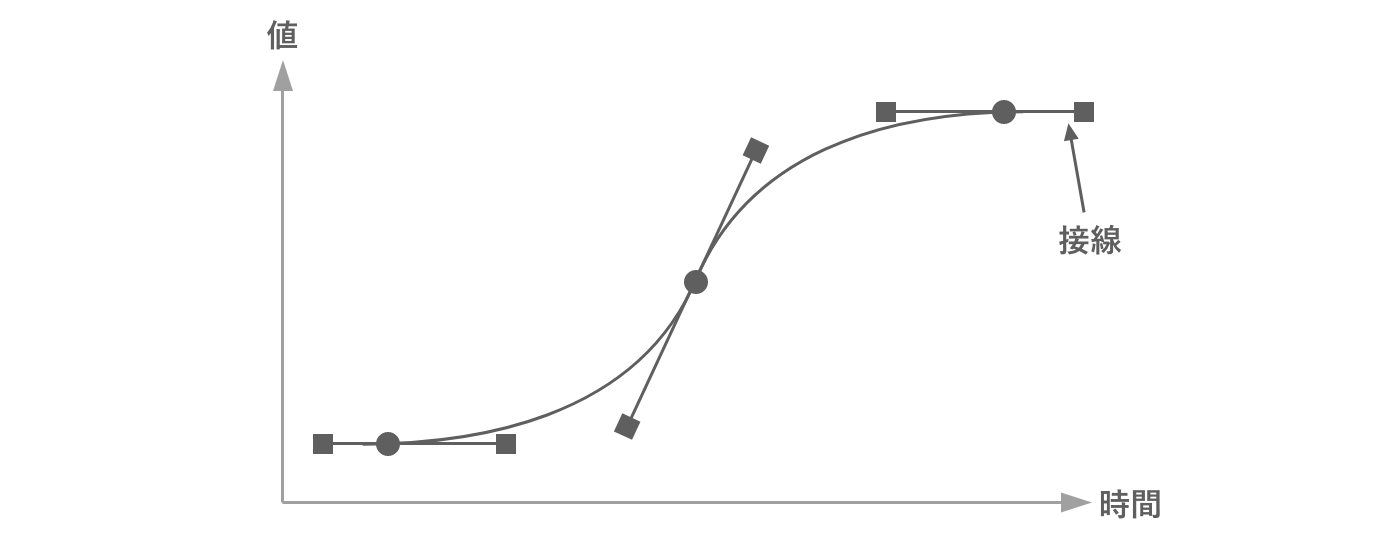
図2.27: 接線と重み
キーフレームアニメーションにおいてはキーフレームが多ければ多いほど複雑なアニメーションを表現できます。しかしながら、データ量もキーフレームの数に応じて増大します。このような理由から、キーフレームの数は適切に設定する必要があります。
できるだけ同じようなカーブを保ちつつキーフレームを削減してデータ量を圧縮する手法もあります。Unityの場合、モデルのインポート設定で次図のようにキーフレームを削減できます。

図2.28: インポート設定
設定方法の詳細は「4.4 Animation」を参照してください。
2.4 Unityの仕組み
Unityエンジンが実際にどういう仕組みで動いているかを理解することは、ゲームをチューニングする上で重要であることはいうまでもありません。この節で知っておくべきUnityの動作原理を説明します。
2.4.1 バイナリとランタイム
まずここではUnityが実際にどういう仕組みでランタイムを動かしているかを解説します。
C#とランタイム
Unityでゲームを作る際、開発者はC#で挙動をプログラミングします。Unityでゲームを開発する際、度々コンパイル(ビルド)が実行されるように、C#はコンパイラ型言語です。ところがC#が伝統的なC言語などと異なるのは、コンパイルするとマシンで単体実行可能な機械語ではなく、.NETにおける中間言語 (Intermediate Language; 以降IL)にコンパイルされることです。ILに変換された実行コードは単体では実行できないので、.NET Frameworkのランタイムを用いて逐次機械語に変換しながら実行されます。
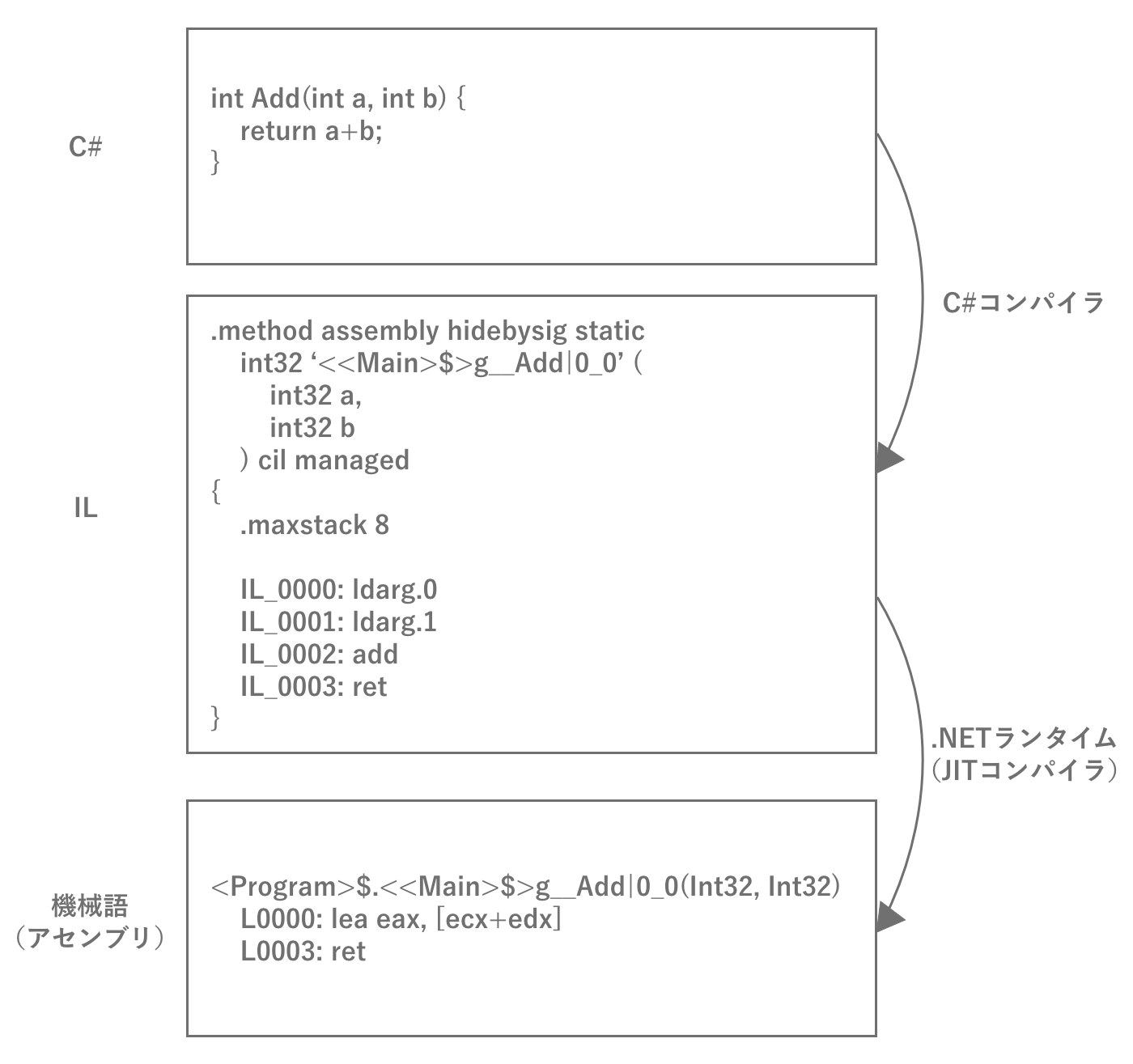
図2.29: C#のコンパイル過程
一度ILを挟むのは、機械語に変換してしまうと単一のプラットフォームでしか実行できないバイナリとなってしまうためです。ILであれば、どのようなプラットフォームでもそのプラットフォームに対応したランタイムを用意するだけで動作するようになるため、プラットフォーム毎にバイナリを用意する必要がなくなります。そのためUnityの基本原理としては、ソースコードをコンパイルして得られたILをそのままそれぞれの環境向けのランタイムで実行することで、マルチプラットフォームを実現しています。
ILコードを確認してみよう
普段は目にすることが少ないILコードは、メモリ確保や実行速度などのパフォーマンスを意識する上で非常に重要です。たとえば配列とListでは、一見同じforeachループでも異なるILコードが出力され、配列の方がパフォーマンスに優れているコードとなります。また意図しない隠れたヒープアロケーションも発見できるかもしれません。こういったC#とILコードの対応感覚を身につけるために、普段から自分の書いたC#コードのIL変換結果を確認しておくことはオススメです。Visual StudioやRiderといったIDEでILコードを閲覧できますが、ILコード自体はアセンブリと呼ばれる低級言語のため理解するのが難しい言語です。そのような場合にはSharpLab*2というWebサービスを利用するとC# -> IL -> C#とILから逆変換したコードを確認することで理解しやすくなります。本書の後半の第10章「Tuning Practice - Script (C#)」にて、実際の変換例を紹介します。
[*2] https://sharplab.io/
IL2CPP
前述のようにUnityでは基本的にはC#をILコードにコンパイルしてランタイムで実行しますが、2015年頃から一部の環境で問題が生じるようになりました。それはiOSやAndroidで動作するアプリの64bit対応です。C#はILコードを実行するためにそれぞれの環境で動作するためのランタイムが必要になるのは前述の通りですが、実はそれまでのUnityは長年.NET FrameworkのOSS実装であるMonoをフォークしてUnity自ら改変して利用していました。つまりUnityが64bit対応するためには、フォークしたMonoを64bit対応させる必要がありました。もちろんそれはとてつもない労力が必要となるため、Unityはここで代わりにIL2CPPと呼ばれる技術を開発することでこの難題を乗り切りました。
IL2CPPとは名前の通りIL to CPPのことであり、ILコードをC++コードに変換する技術です。C++はどのような開発環境でもネイティブサポートされるような汎用性の高い言語であるため、C++コードに出力してしまえばそれぞれの開発ツールチェインにて機械語にコンパイルすることが可能です。したがって64bit対応はツールチェインの仕事となるため、Unity側はその対応をする必要がなくなります。またC#と違ってビルド時点で機械語にコンパイルされるため、ランタイムにて機械語に変換する必要がなくなり、パフォーマンスが向上するという恩恵もあります。
C++コードは一般的にビルドに時間を要するという欠点はありますが、64bit対応とパフォーマンスを一挙に解決するIL2CPPという技術はUnityの要となりました。
Unityランタイム
ところでUnityでは開発者はC#でゲームをプログラミングしますが、エンジンと呼ばれるUnity自体のランタイムは実はC#で動いているわけではありません。ソース自体はC++で記述され、プレイヤーと呼ばれる部分は各環境で実行するために事前にビルドされた状態で配布されます。UnityがエンジンをC++で記述するのは、いくつかの理由が考えられます。
- 高速かつ省メモリのパフォーマンスを得るため
- なるべく多くのプラットフォームに対応するため
- エンジンの知的財産権の保護のため(ブラックボックス化)
開発者が記述したC#コードはあくまでC#で動作するため、Unityではネイティブで動作するエンジン部分と、C#ランタイムで動作するユーザーコード部分に2つの領域が必要となります。エンジンとユーザーコードは、実行中に適宜データをやり取りすることで動作しています。たとえばGameObject.transformをC#から呼び出した場合、シーンの状態などゲームの実行状態はすべてエンジン内部で管理されているため、まずネイティブ呼び出しを行ってネイティブ領域のメモリデータにアクセスし、C#に値を返すという手順を踏んでいます。ここで注意したいのは、C#とネイティブではメモリは共有されないため、C#で必要となったデータは都度C#側でメモリが確保されることです。またAPI呼び出しもネイティブ呼び出しが発生するなど高価なものになるため、頻繁に呼び出さずに値をキャッシュするという最適化手法が必要となります。
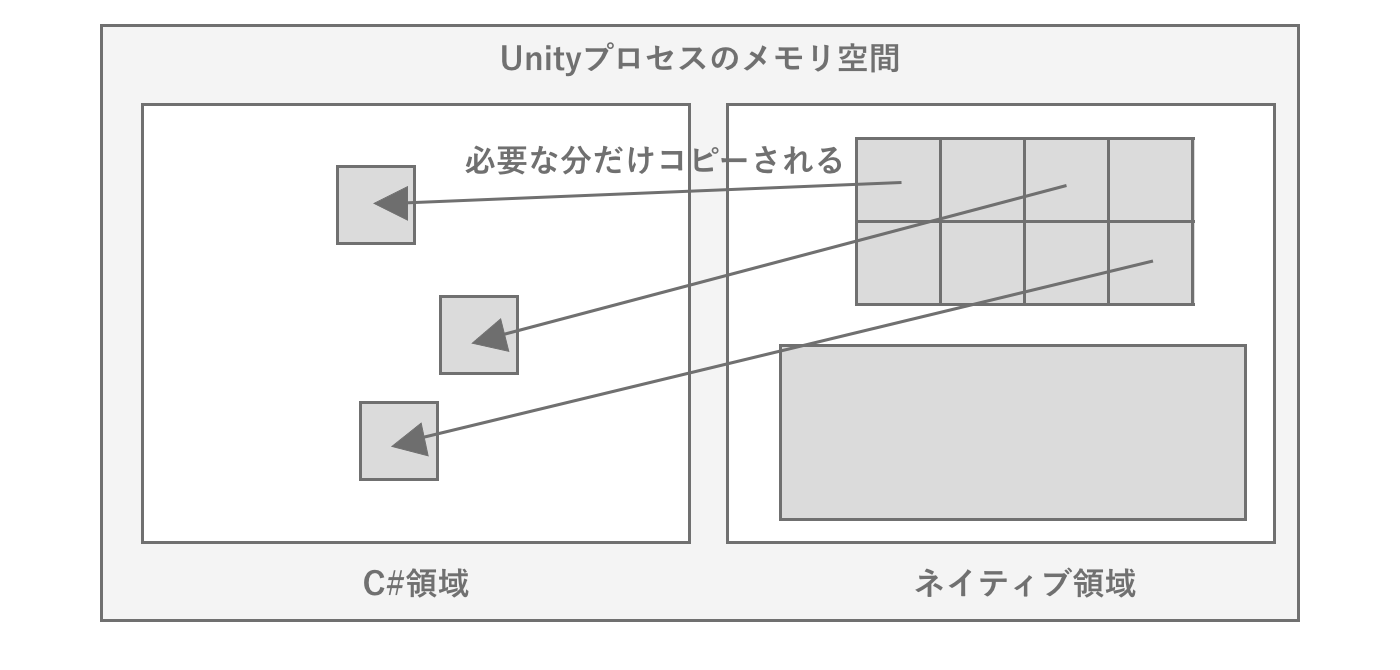
図2.30: Unityにおけるメモリの状態イメージ
このように、Unityを開発する上では見えないエンジン部分もある程度意識する必要があります。そのため適宜Unityエンジンのネイティブ領域とC#を繋ぐインターフェイスのソースコードを見るとよいでしょう。幸いにもUnity社がC#の部分であればGitHubで公開*3しているため、ほとんどネイティブ呼び出しになっていることがわかるなど非常に役立ちます。必要に応じて活用することをオススメします。
2.4.2 アセットの実体
前節で説明したように、Unityエンジンはネイティブで実行されているため、基本的にはC#側ではデータを持ちません。アセットの取り扱いに関しても同様で、ネイティブ領域でアセットをロードし、C#に参照を返したり、データをコピーして返していたりするだけです。そのためアセットをロードする際は、大別すると、Unityエンジン側でロードさせるためにパスを指定をする方法と、バイト配列など生データを直接渡す方法の2種類があります。パスを指定した場合はネイティブ領域でロードするためC#側でメモリを消費することはありませんが、バイト配列などデータをC#側からロード・加工して渡した場合はC#側とネイティブ側で二重にメモリを消費してしまいます。
またアセットの実体がネイティブ側にあるため、アセットの多重ロードやリークに関する調査の難易度も上がります。これは開発者は主にC#側のプロファイリングやデバッグを中心に行うためです。C#側の実行状態だけ見ても理解することは難しく、エンジン側の実行状態と突き合わせながら解析する必要がありますが、ネイティブ領域のプロファイリングはUnityが提供するAPIに依存するためツールが限られるという問題があります。本書でさまざまなツールを駆使して分析する手法を紹介しますが、その際にC#とネイティブの空間を意識すると理解しやすくなります。
2.4.3 スレッド
スレッドはプログラムの実行単位で、一般的には1つのプロセスの中に複数のスレッドを生成しながら処理が進みます。CPUの1つのコアは同時に1つのスレッドしか処理することができないため、複数のスレッドを処理するために高速にスレッドを切り替えながらプログラムを実行します。これをコンテキストスイッチと呼びます。コンテキストスイッチする際はオーバーヘッドが生じるため、頻繁に発生すると処理効率が低下してしまいます。
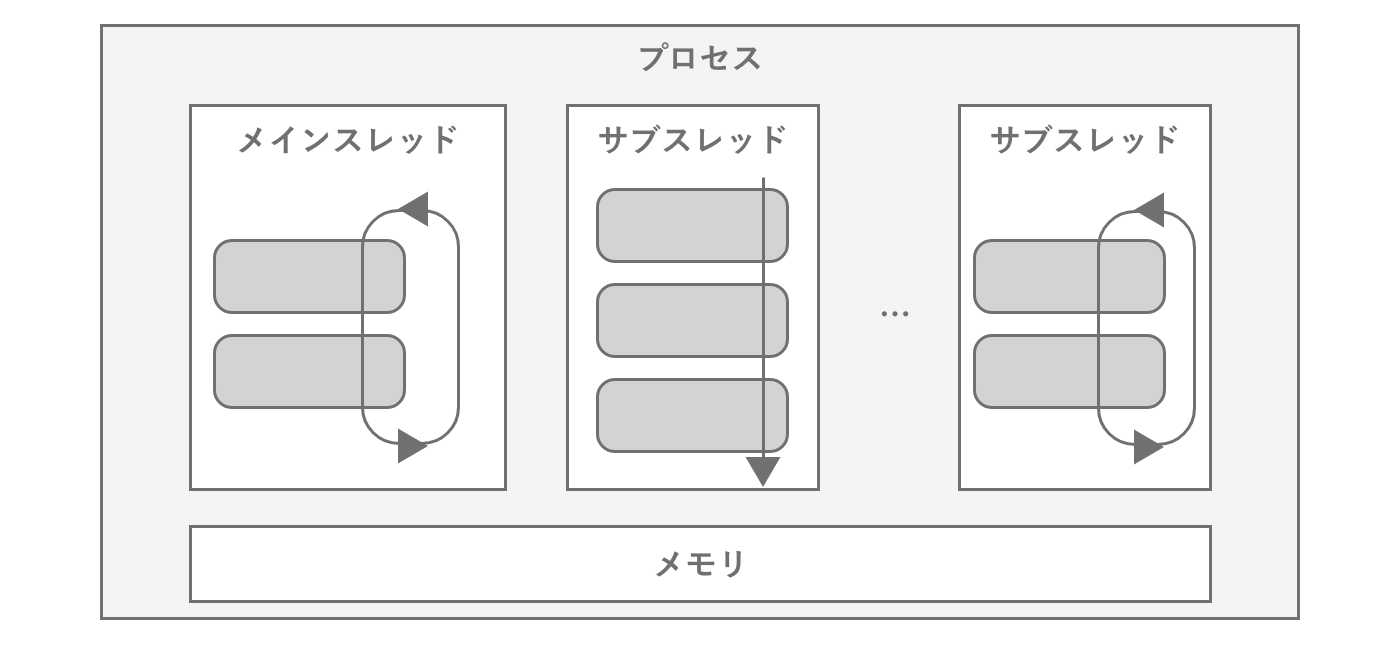
図2.31: スレッドの模式図
プログラムの実行時には基底となるメインスレッドが生成され、そこからプログラムが必要に応じて別のスレッドを生成・管理します。Unityのゲームループはシングルスレッドで動作する設計となっているため、ユーザーが記述したスクリプトは基本的にはメインスレッド上で動作することになります。逆にメインスレッド以外からUnity APIを呼び出そうとすると、ほとんどのAPIはエラーが発生してしまいます。
メインスレッドから別のスレッドを作成して処理を実行する場合、そのスレッドがいつ実行されて、いつ完了するかはわかりません。そのためスレッド間で処理を同期させる手段としてシグナルと呼ばれる機構があります。別スレッドの処理を待機する場合、そのスレッドからシグナルを通知してもらうことで待機を解除できます。このシグナル待機はUnity内部でも使われているためプロファイリング時などに観測できますが、WaitFor~という名前の通りただ別の処理を待機しているだけということは注意しましょう。
Unity内部のスレッド
とはいえあらゆる処理をメインスレッドで実行していると、プログラム全体の処理に時間がかかるようになってしまいます。複数の重い処理があり、それが相互に依存がなかった場合、ある程度処理を同期することで並列処理を行うことができれば、プログラムの実行を短縮することが可能となります。こうした高速化のために、ゲームエンジン内部では並列処理が多数用いられます。その1つがレンダースレッド (Render Thread)です。名前の通りレンダリング専用のスレッドで、メインスレッドで計算したフレームの描画情報を、グラフィックスコマンドとしてGPUに送る役割を担います。
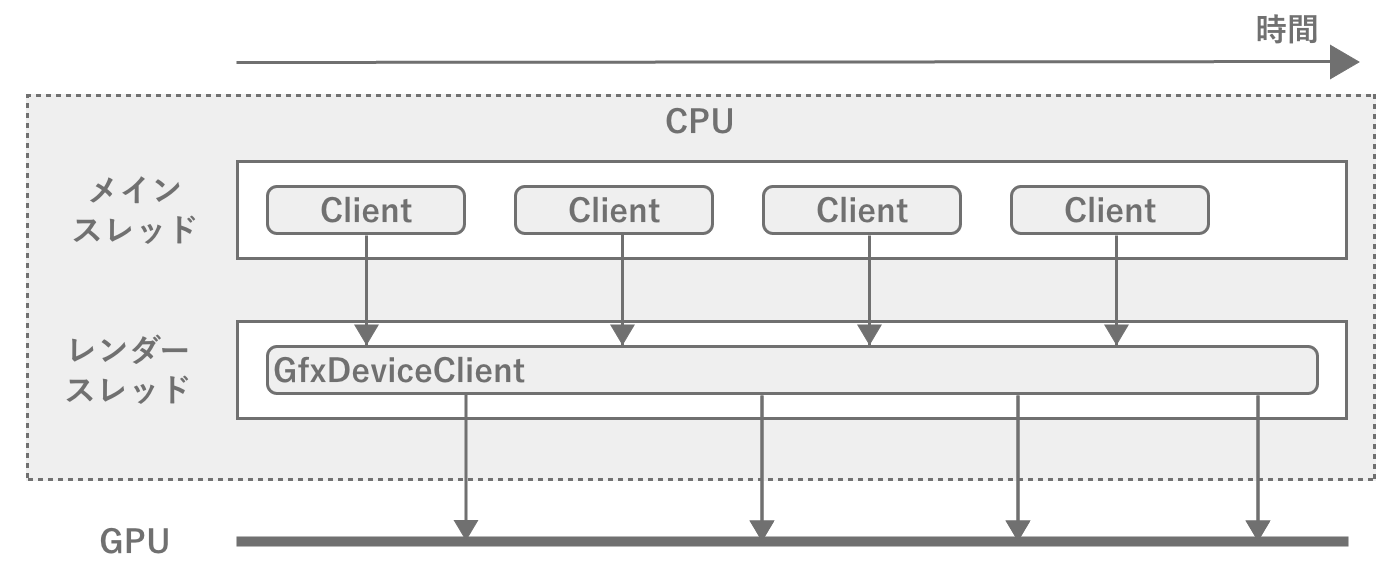
図2.32: メインスレッドとレンダースレッド
メインスレッドとレンダースレッドはパイプラインのように実行されるため、レンダースレッドが処理中に次のフレームの計算が始まります。ところがもしレンダースレッド内で1フレームを処理する時間が長くなってくると、次のフレームの描画の計算が終わったとしても描画を開始することができなくなり、メインスレッドは待たされることになります。ゲーム開発ではメインスレッド、レンダースレッドどちらが重くなってもFPSが低下してしまうため注意しましょう。
並列処理可能なユーザー処理のスレッド化
またゲーム特有の部分として、物理エンジンや揺れものなど並列処理を実行できる計算タスクが多数存在します。そのような計算をメインスレッド以外で実行させるために、Unityではワーカースレッド (Worker Thread)が存在します。ワーカースレッドはJobSystemを通して生成された計算タスクを実行します。JobSystemを利用することでメインスレッドの処理負荷を軽減できる場合は積極的に利用しましょう。もちろんJobSystemを利用せずに、自前でスレッドを生成する方法もあります。
スレッドはパフォーマンスチューニングで便利な半面、使いすぎると逆にパフォーマンスが低下したり、処理の複雑性が向上する危険性もあるため、闇雲に使わないことをオススメします。
2.4.4 ゲームループ
Unityを含む一般的なゲームエンジンは、ゲームループ (プレイヤーループ)と呼ばれる、エンジンのルーチン処理があります。簡潔にループを表現するのならば、概ね以下のようになります。
- キーボード、マウス、タッチディスプレイなどのコントローラーの入力処理
- 1フレームの時間で進行すべきゲームの状態を計算
- 新しいゲームの状態をレンダリング
- ターゲットFPSに応じて、次のフレームまで待機
このループを繰り返すことでゲームを映像としてGPUに出力します。もし1フレーム内の処理に時間がかかるようになると、もちろんFPSが低下することになります。
Unityにおけるゲームループ
Unityにおけるゲームループは、皆さん一度は見たことがあるUnityの公式リファレンスにゲームループの模式図*4が存在します。
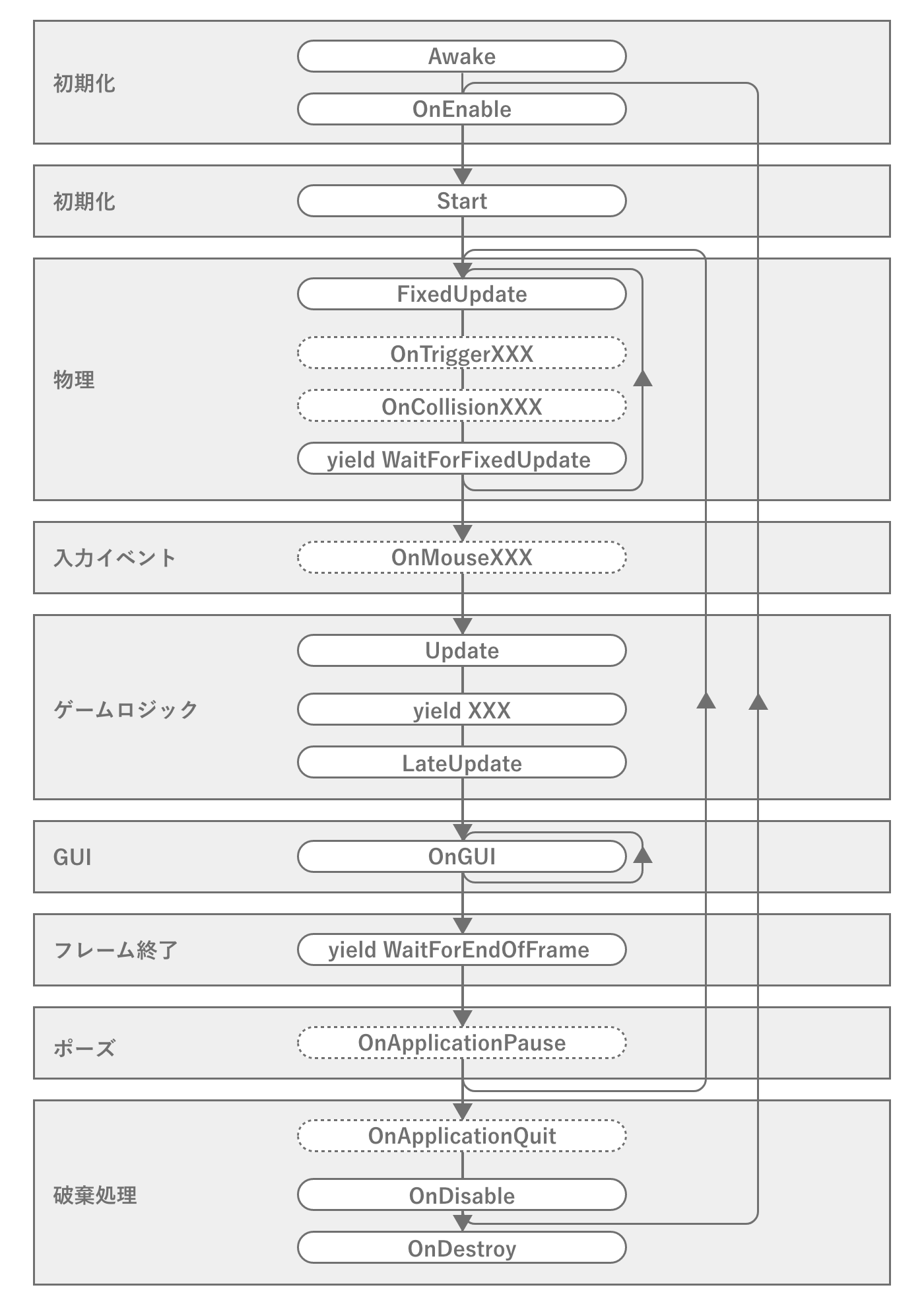
図2.33: Unityのイベントの実行順序
この図は厳密にはMonoBehaviourのイベントの実行順を表したもので、ゲームエンジンとしてのゲームループ*5とは異なりますが、開発者が知っておくべきゲームループとしてはこれで十分です。とくに重要なイベントとして、Awake, OnEnable, Start, FixedUpdate, Update, LateUpdate, OnDisable, OnDestroyと各種コルーチンの処理タイミングです。イベントの実行順やタイミングを勘違いしてしまうと、思わぬメモリリークや余計な計算につながってしまう可能性があります。そのため重要イベントの呼び出しタイミングや、同イベント内での実行順序などの性質は把握しておくべきでしょう。
物理演算に関しては、通常のゲームループと同じ間隔で実行していると衝突判定されずにオブジェクトがすり抜けてしまうなど特有の問題があります。そのため通常は物理演算ルーチンのループを高頻度に回すように、ゲームループとは異なる間隔でループを回します。ただ闇雲に回すとメインのゲームループの更新処理と競合する可能性があるため、ある程度は処理を同期させる必要があります。そのため物理演算が必要以上に重くなるとフレームの描画処理に影響したり、またフレームの描画処理が重くなると物理演算が遅れてすり抜けが発生したりと、互いに影響する可能性があるため注意しましょう。
2.4.5 GameObject
前述のように、Unityのエンジン自体はネイティブで動作しているため、C#のUnity APIもその大部分は内部のネイティブAPIを呼び出すためのインターフェイスです。それはGameObjectやそれにアタッチするコンポーネントを定義するMonoBehaviourも同様で、常にC#側からネイティブの参照を持ち続けることになります。ところがネイティブ側でデータを管理しつつ、C#側でもそれらの参照を持っている場合、破棄のタイミングで不都合が発生します。それはネイティブ側で破棄されたデータに対して、C#からの参照を勝手に消すことができないからです。
実際にリスト2.1で破棄したGameObjectがnullかどうかチェックしていますが、ログにはtrueが出力されます。これは標準のC#の挙動としては不自然で、_gameObjectにはnullを代入していないためGameObject型のインスタンスの参照が残っているはずです。
リスト2.1: 破棄後の参照テスト
public class DestroyTest : UnityEngine.MonoBehaviour
{
private UnityEngine.GameObject _gameObject;
private void Start()
{
_gameObject = new UnityEngine.GameObject("test");
StartCoroutine(DelayedDestroy());
}
System.Collections.IEnumerator DelayedDestroy()
{
// cache WaitForSeconds to reuse
var waitOneSecond = new UnityEngine.WaitForSeconds(1f);
yield return waitOneSecond;
Destroy(_gameObject);
yield return waitOneSecond;
// _gameObject is not null, but result is true
UnityEngine.Debug.Log(_gameObject == null);
}
}
これはUnityのC#側の仕組みで、破棄済みデータへのアクセスの制御を行っているからです。実際にUnityのC#実装部のUnityEngine.Objectのソースコード*6を参照すると、以下のようになっています。
リスト2.2: UnityEngine.Objectの==オペレーターの実装
// 抜粋
public static bool operator==(Object x, Object y) {
return CompareBaseObjects(x, y);
}
static bool CompareBaseObjects(UnityEngine.Object lhs,
UnityEngine.Object rhs)
{
bool lhsNull = ((object)lhs) == null;
bool rhsNull = ((object)rhs) == null;
if (rhsNull && lhsNull) return true;
if (rhsNull) return !IsNativeObjectAlive(lhs);
if (lhsNull) return !IsNativeObjectAlive(rhs);
return lhs.m_InstanceID == rhs.m_InstanceID;
}
static bool IsNativeObjectAlive(UnityEngine.Object o)
{
if (o.GetCachedPtr() != IntPtr.Zero)
return true;
if (o is MonoBehaviour || o is ScriptableObject)
return false;
return DoesObjectWithInstanceIDExist(o.GetInstanceID());
}
要約すると、null比較をしたときはネイティブ側のデータが存在するかどうかをチェックしているために、破棄されたインスタンスへのnull比較がtrueになります。そのためにnullでないGameObjectのインスタンスが一部nullのように振る舞います。この特性は一見すると便利なのですが、非常に厄介な側面もあります。それは_gameObjectは実際にはnullではないので、メモリリークを引き起こすからです。_gameObject1個分のメモリリークは当然ですが、たとえばそのコンポーネントの中からマスターなどの巨大なデータへの参照を持っている場合、C#としては参照が残るため、ガベージコレクションの対象とはならないので巨大なメモリリークに繋がってしまいます。これを回避するためには、_gameObjectにnullを代入するなどの対策が必要となります。
2.4.6 AssetBundle
スマホ向けゲームはアプリのサイズに制限があり、すべてのアセットをアプリに含めることができません。そのため必要に応じてアセットをダウンロードするために、UnityにはAssetBundleという複数のアセットをパッキングして、動的にロードする仕組みがあります。一見簡単に扱えるように感じるかもしれませんが、大規模プロジェクトの場合は適切に設計しないと思わぬところでメモリをムダに使ってしまうなど、メモリやAssetBundleに対する十分な理解と丁寧な設計が求められます。そのためこの節ではAssetBundleについてチューニングの観点で知っておくべきことを説明します。
AssetBundleの圧縮設定
AssetBundleはビルド時にデフォルトでLZMA圧縮されます。これをBuildAssetBundleOptionsのUncompressedAssetBundleに変えることで無圧縮に、ChunkBasedCompressionに変えることでLZ4圧縮に変更することが可能です。これらの設定の差は以下の表2.4のような傾向があります。
表2.4: AssetBundleの圧縮設定による違い
| 項目 | 無圧縮 | LZMA | LZ4 |
|---|---|---|---|
| ファイルサイズ | 特大 | 特小 | 小 |
| ロード時間 | 速い | 遅い | かなり速い |
つまりロード時間を最速にするなら無圧縮がよいですが、ファイルサイズが致命的に大きくなるためスマートフォンにおける記憶領域の浪費を避けるためには基本的に使用できません。一方でLZMAはファイルサイズが一番小さくなりますが、アルゴリズムの問題で展開に時間がかかる、部分的な展開処理ができないという欠点があります。LZ4は速度とファイルサイズのバランスのよい圧縮設定で、ChunkBasedCompressionの名の通り部分展開が可能なためLZMAのように全体を展開しなくても部分読み込みが可能です。
またAssetBundleには端末キャッシュ時に圧縮設定を変えるCaching.compressionEnabledがあります。つまり配信はLZMAで、端末でLZ4に変換することで、ダウンロードサイズを最小にしつつ、実際に使う際にはLZ4の恩恵を受けられるようになります。ただし端末側で再圧縮するということは、それだけ端末でのCPUの処理コストがかかる、メモリや記憶領域を一時的に浪費してしまうといった問題があります。
AssetBundleの依存関係と重複
あるアセットが複数のアセットから依存されている場合、AssetBundle化する際には注意が必要です。たとえばマテリアルAとマテリアルBがテクスチャCに依存している場合、テクスチャをAssetBundle化せずに、マテリアルAとBだけAssetBundle化すると、生成される2つのAssetBundleのそれぞれにテクスチャCが含まれるため、重複してムダになってしまいます。もちろん容量を使うという点でもムダなのですが、2つのマテリアルをメモリにロードする際にテクスチャが別々にインスタンス化されるため、メモリもムダにしてしまいます。
同一アセットが複数のAssetBundleに含まれるのを避けるためには、テクスチャCも単体でAssetBundle化してマテリアルのAssetBundleから依存される形にするか、マテリアルA、BとテクスチャCを1つにしたAssetBundleにする必要があります。
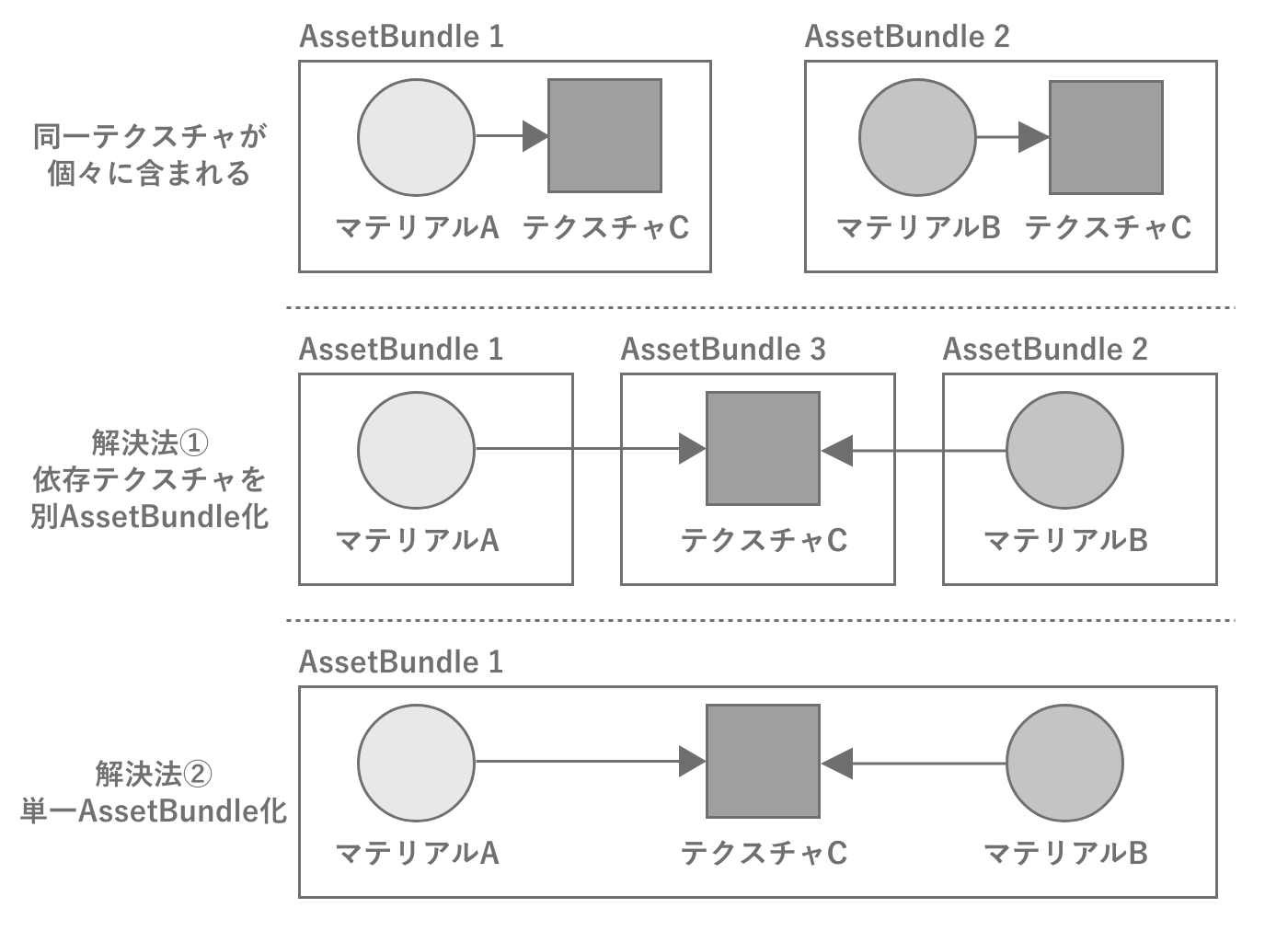
図2.34: AssetBundleの依存関係がある例
AssetBundleからロードされたアセットの同一性
AssetBundleからのアセットをロードする時の重要な性質として、AssetBundleがロードされている間は同じアセットを何度ロードしても同じインスタンスが返ってきます。これはUnity内部でロード済みのアセットを管理していることを示し、Unity内部ではAssetBundleとアセットは紐付けられた状態になります。この性質を利用することで、ゲーム側でアセットのキャッシュ機構を作らずにUnity側に委ねることも可能です。
ただしAssetBundle.Unload(false)でアンロードした場合のアセットは、図2.35のように再度同じAssetBundleから同じアセットをロードしても別インスタンスとなるため、注意が必要です。これはアンロードするタイミングでAssetBundleとアセットの紐付けが解除されるためで、アセットの管理が宙に浮いた状態に状態になるためです。
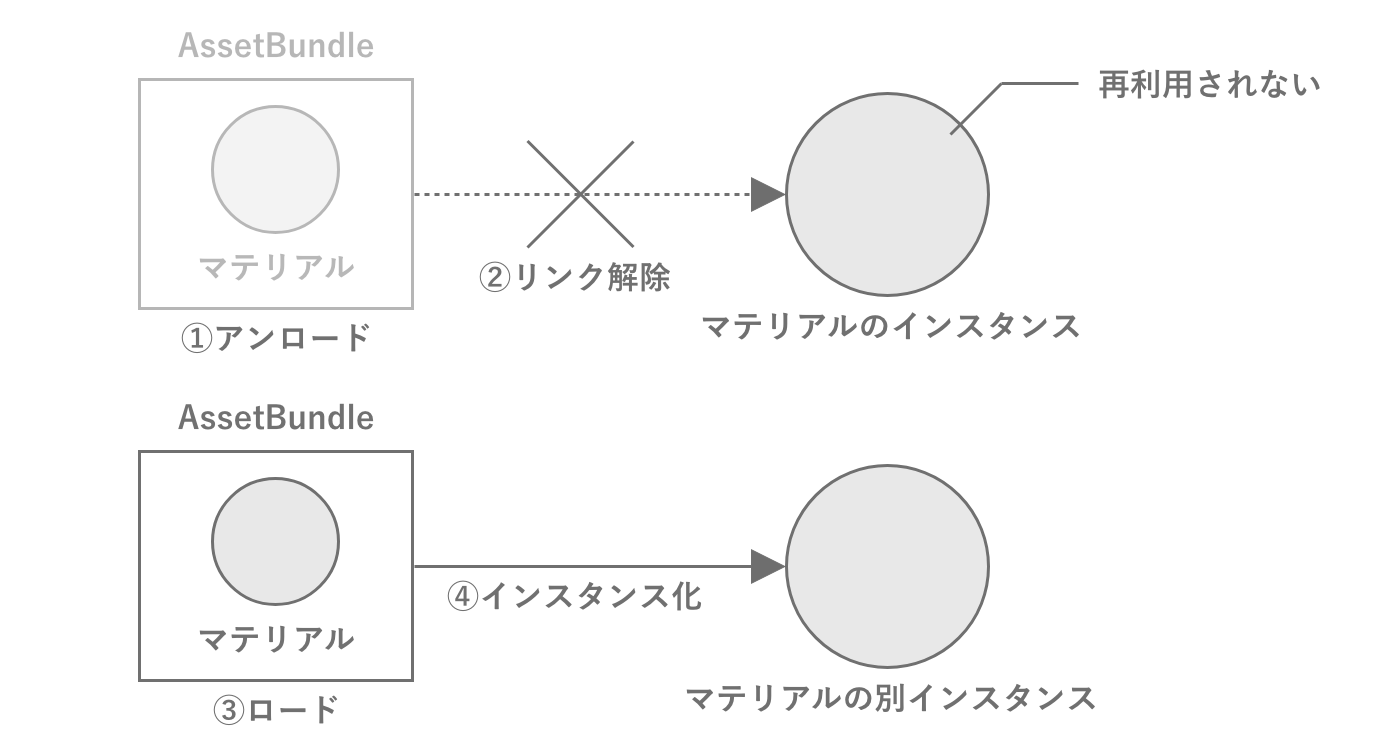
図2.35: AssetBundleとアセットの管理が不適切でメモリリークする例
AssetBundleからロードしたアセットの破棄
AssetBundle.Unload(true)でAssetBundleをアンロードする場合は、ロードしたアセットも完全に破棄されるためにメモリに関してとくに困ることはありませんが、AssetBundle.Unload(false)を使用する場合は適切なタイミングでアセットのアンロード命令を呼び出さないとアセットが破棄されません。そのため後者を使用する場合は、シーン切替時などでアセットが破棄されるように適切にResources.UnloadUnusedAssetsを呼び出す必要があります。またResources.UnloadUnusedAssetsの名前の通り、参照が残っている場合は解放されないことにも注意が必要です。なお、Addressableを使用する場合は内部でAssetBundle.Unload(true)を呼び出します。
2.5 C#の基礎知識
この節では、パフォーマンスチューニングをする上で欠かせない、C#の言語仕様やプログラム実行時の挙動について説明します。
2.5.1 スタックとヒープ
「スタックとヒープ」ではプログラム実行時のメモリ管理方式としてのスタックとヒープが存在することを紹介しました。スタックはOSが管理するのに対して、ヒープはプログラム側が管理します。つまりヒープメモリがどうやって管理されているかを知ることで、メモリを意識した実装を行うことができます。ヒープメモリの管理の仕組みは、プログラムの元となったソースコードの言語仕様に依るところが大きいので、C#におけるヒープメモリの管理について解説します。
本来のヒープメモリは必要なタイミングでメモリ確保し、使い終わったらメモリを解放する必要があります。もしメモリを解放しない場合はメモリリークとなり、アプリケーションが使うメモリ領域が膨らみ、最終的にはクラッシュに繋がってしまいます。ところがC#には明示的なメモリ解放処理はありません。これはC#のプログラムが実行される.NETランタイム環境では、ヒープメモリがランタイムによって自動で管理され、使い終わったメモリは適切なタイミングで解放されるためです。このためヒープメモリのことをマネージドヒープとも呼びます。
スタックに確保されたメモリは関数のライフタイムと一致するので、関数の最後にメモリを解放してあげるだけでよいのですが、ヒープで確保されたメモリは関数のライフタイムを超えて生存することがほとんどです。つまりヒープメモリを必要としたり使い終わったりするタイミングがさまざまであるため、自動かつ効率よくヒープメモリを使うための仕組みが必要になります。詳細については次の項で紹介しますが、その仕組みをガベージコレクション (Garbage Collection)と呼びます。
実はUnityにおけるGC.Allocは独自の用語で、ガベージコレクションで管理されているヒープメモリに確保(Allocation)されたメモリのことを表しています。そのためGC.Allocを減らすことは、動的に確保されるヒープメモリの量を減らすことになります。
2.5.2 ガベージコレクション
C#のメモリ管理において、未使用のメモリの検索や解放はガベージコレクション、略して「GC」と呼ばれます。ガベージコレクターは周期的に実行されます。ただし、正確な実行タイミングはアルゴリズムによって異なります。これにより、ヒープ上のすべてのオブジェクトが一斉調査され、すでに参照されなくなっているすべてのオブジェクトが削除されます。つまり、参照の外されたオブジェクトが削除され、メモリ領域が解放されます。
ガベージコレクターにはさまざまなアルゴリズムがありますが、UnityではデフォルトでBoehm GCアルゴリズムが使用されています。Boehm GCアルゴリズムの特徴は、「非世代別」で「非圧縮型」であることです。「非世代別」とは、ガベージコレクションを1回実行するごとにヒープ全体を一斉調査しなければならないことを意味しています。このため、ヒープが拡張するのに応じて検索範囲も拡がるためパフォーマンスが低下します。「非圧縮型」とは、オブジェクト同士の隙間を詰めるためにメモリ内のオブジェクト移動が行われないことを意味します。つまり、メモリ上に細かい隙間を生む断片化が起こりやすく、マネージヒープの拡張がされやすい傾向にあります。
それぞれ計算コストが高い処理でありかつ他の処理をすべて止めてしまう同期的な処理であるため、ゲーム中に走るといわゆる「Stop the World」と呼ばれる処理落ちの原因に繋がります。
Unity 2018.3からはGCModeを指定できるようになり、一時的に無効化することが可能になりました。
リスト2.3:
GarbageCollector.GCMode = GarbageCollector.Mode.Disabled; |
しかし、当然のことながら無効化している期間にGC.Allocをしてしまうと、ヒープ領域は拡張かつ消費され、最終的には新たに確保できなくなりアプリのクラッシュへと繋がります。メモリ使用量は簡単に増大していくため、無効化している期間ではGC.Allocが一切行われないように実装する必要があり、実装コストも高くなることから実際に利用できる場面は限られています。(例: シューティングゲームのシューティングパートのみ無効化するなど)
また、Unity 2019からIncremental GCが選択できるようになりました。Incremental GCでは、ガベージコレクションの処理がフレームを跨いで行われるようになり、大きなスパイクは以前より軽減可能になりました。しかしながら、1フレームあたりの処理時間を削減しつつ最大限のパワーを発揮しなければならないようなゲームの場合、突き詰めるとGC.Allocの発生を避けた実装が必要になります。具体的な例については、「10.1 GC.Allocするケースと対処法」で述べます。
いつから取り組むべきか
ゲームはコード量も多くなるため、全機能実装完了してからパフォーマンスチューニングを実施すると往々にしてGC.Allocを回避できないような設計/実装に遭遇してしまうことがあります。設計初期段階から、どこで発生するのか常に意識した上でコーディングしていくと、作り直しによるコストも軽減できるようになり、トータルでの開発効率は改善される傾向にあります。
理想的な実装の流れとしては、まずはスピード重視でプロトタイプを制作し手触りや遊びのコアとなる部分を検証し、その次の本制作フェーズに進む際に一度設計を見直し再構築します。この再構築するフェーズでGC.Allocの撲滅に取り組むと健全でしょう。場合によってはコードの可読性を下げてでも高速化を図る必要も出てくるため、プロトタイプから取り組んでいては開発速度も低下してしまいます。
2.5.3 構造体(struct)
C#では複合型の定義はクラスと構造体が存在します。大前提、クラスは参照型、構造体は値型となります。MSDNの「Choosing Between Class and Struct」*7を引用しつつ、それぞれの特性と選択すべき基準、使い方の注意事項について確認します。
[*7] https://docs.microsoft.com/en-us/dotnet/standard/design-guidelines/choosing-between-class-and-struct
メモリの割り当て先の違い
参照型と値型の1つ目の違いは、メモリの割り当て先が異なる点です。少々正確性には欠けますが、次のように認識しておいて問題はありません。参照型はメモリ上のヒープ領域に割り当てられ、ガベージコレクションの対象となります。値型はメモリ上のスタック領域に割り当てられ、ガベージコレクションの対象にはなりません。値型の割り当てと割り当て解除は、参照型よりも一般的に低コストです。
ただし、参照型のフィールドに宣言されている値型やstatic変数はヒープ領域に割り当てられます。このため、構造体として定義した変数が必ずしもスタック領域に割り当てられるわけではない点に注意しましょう。
配列の扱い
値型の配列はインラインで割り当てられ、配列要素は値型の実体(インスタンス)がそのまま並びます。一方、参照型の配列では、配列要素は参照型の実体への参照(アドレス)が並びます。したがって、値型の配列の割り当てと割り当て解除は、参照型よりもはるかに低コストです。また、ほとんどの場合、値型の配列は参照の局所性(空間的局所性)が大幅に向上するため、CPUキャッシュメモリのヒット確率が高くなり、処理が高速化しやすくなるメリットがあります。
値のコピー
参照型の代入(割り当て)では、参照(アドレス)がコピーされます。一方、値型の代入(割り当て)では、値全体がコピーされます。アドレスのサイズは32bit環境の場合で4バイト、64bit環境の場合で8バイトとなります。したがって、大きな参照型の割り当ては、アドレスサイズより大きな値型の割り当てよりも低コストです。
また、メソッドを用いたデータのやり取り(引数・戻り値)に関しても、参照型は参照(アドレス)が値渡しされるのに対し、値型はインスタンスそのものが値渡しされます。
リスト2.4:
private void HogeMethod(MyStruct myStruct, MyClass myClass){...} |
たとえばこちらのメソッドでは、MyStructの値全体がコピーされます。つまり、MyStructのサイズが大きくなるとその分コピーコストも増大します。一方MyClassの方では、myClassの参照が値としてコピーされるだけになるため、MyClassのサイズが増大してもコピーコストはアドレスサイズ分のみであるため一定になります。コピーコストの増加は処理負荷に直結するため、扱うデータサイズに応じて適切に選択する必要があります。
不変性
参照型のインスタンスに加えた変更は、同じインスタンスを参照している別の場所にも影響します。一方、値型のインスタンスは、値渡しされるときにコピーが生成されます。値型のインスタンスが変更された場合、当然、そのインスタンスのコピーには影響しません。コピーはプログラマによって明示的に作成されるのではなく、引数が渡されるとき、または戻り値が返されるときに暗黙的に作成されます。プログラマとしては値を変更したつもりが、実はコピーに対して値をセットしていただけで、目的の処理とは異なっていたという不具合を一度は経験していることでしょう。変更可能な値型は多くのプログラマに混乱を招くおそれがあるため、値型は不変であることが推奨されています。
参照渡し
よくある誤用で「参照型は常に参照渡しになる」が挙げられますが、先述した通り参照(アドレス)のコピーが基本であり、参照渡しはref/in/outパラメーター修飾子を用いたときに行われます。
リスト2.5:
private void HogeMethod(ref MyClass myClass){...} |
参照型の値渡しでは参照(アドレス)がコピーされていたため、インスタンスの置き換えをしてもコピー元のインスタンスには影響しませんでしたが、参照渡しにすると元のインスタンスの置き換えも可能になります。
リスト2.6:
private void HogeMethod(ref MyClass myClass) { // 引数で渡された元のインスタンスを書き換えてしまう myClass = new MyClass(); } |
ボックス化
ボックス化とは、値型からobject型、または値型からインターフェイス型へ変換するプロセスのことです。ボックスはヒープに割り当てられ、ガベージコレクションの対象になるオブジェクトです。そのため、ボックス化とボックス化解除が過剰になると、GC.Allocが発生します。これに対し、参照型がキャストされるとき、このようなボックス化は行われません。
リスト2.7: 値型からobject型にキャストするとボックス化
int num = 0; object obj = num; // ボックス化 num = (int) obj; // ボックス化解除 |
このようにわかりやすく無意味なボックス化を使うことはありませんが、メソッドで使われている場合はどうでしょうか。
リスト2.8: 暗黙キャストでボックス化が行われる例
private void HogeMethod(object data){ ... } // 中略 int num = 0; HogeMethod(num); // 引数でボックス化 |
このようなケースで、無意識のうちにボックス化してしまっているケースは存在します。
簡単な代入と比べて、ボックス化およびボックス化解除は負荷の大きいプロセスです。値型をボックス化するときは、新しいインスタンスを割り当てて構築する必要があります。また、ボックス化ほどではありませんが、ボックス化解除に必要なキャストも大きな負荷がかかります。
クラスと構造体を選ぶ基準について
- 構造体を検討すべき条件:
- 型のインスタンスが小さく、有効期間が短いことが多い場合
- 他のオブジェクトに埋め込まれることが多い場合
- 構造体を避ける条件: ただし、型が次のすべての特性を持つ場合を除く
- プリミティブ型(
int、doubleなど)と同様に、論理的に単一の値を表すとき - インスタンスのサイズが16バイト未満である
- 不変(イミュータブル)である
- 頻繁にボックス化する必要がない
- プリミティブ型(
上記の選択条件に当てはまらないものの、構造体と定義されている型も多数存在しています。Unityで頻繁に使用されているVector4やQuaternionなど、16バイト未満ではありませんが構造体で定義されています。これらを効率よく扱う方法を確認した上で、コピーコストが増大しているようでしたら回避する方法を含めて選択し、場合によっては自前で同等の機能を持った最適化版を作ることも検討してください。
2.6 アルゴリズムと計算量
ゲームプログラミングにはさまざまなアルゴリズムが利用されます。アルゴリズムは作り方次第で計算結果は同じでも、途中の計算過程が異なることでパフォーマンスは大きく変わることがあります。たとえば、C#に標準で用意されているアルゴリズムはどれくらい効率のよいものなのか、あなたが実装したアルゴリズムはどれくらい効率のよいものなのか、それぞれ評価する尺度が欲しくなります。これらを測る目安として、計算量という指標が用いられています。
2.6.1 計算量について
計算量とはアルゴリズムの計算効率を測る尺度のことで、細かく分けると時間効率を測る時間計算量やメモリ効率を測る領域計算量などがあります。計算量オーダーはO記法(ランダウの記号)で表されます。計算機科学や数学的な定義などはここでは本質ではないため、気になる方は他の書籍を参照してください。また、本稿では計算量と記載しているものは時間計算量として取り扱います。
一般的に使われるおもな計算量はO(1)、O(n)、O(n^2)、O(n\log n)のように表記されます。括弧内のnはデータ数を示しています。ある処理がどれくらいデータ数に依存して処理回数が増えていくかをイメージするとわかりやすいでしょう。計算量の観点から性能を比較すると、O(1) < O(\log n) < O(n) < O(n\log n) < O(n^2) < O(n^3)となります。表2.5にデータ数と計算ステップ数の比較と、図2.36に対数表示した比較グラフを示しました。O(1)はデータ数によらないため比べるまでもなく明らかに性能が高いため除いてあります。たとえば、O(\log n)はデータ数が1万サンプルあったとしても計算ステップ数は13、1,000万サンプルあったとしても計算ステップ数が23回と極めて優秀であることがわかります。
表2.5: おもな計算量におけるデータ数と計算ステップ数
| n | O(\log n) | O(n) | O(n\log n) | O(n^2) | O(n^3) |
|---|---|---|---|---|---|
| 10 | 3 | 10 | 33 | 100 | 1,000 |
| 100 | 7 | 100 | 664 | 10,000 | 1,000,000 |
| 1,000 | 10 | 1,000 | 9,966 | 1,000,000 | 1,000,000,000 |
| 10,000 | 13 | 10,000 | 132,877 | 100,000,000 | 1,000,000,000,000 |
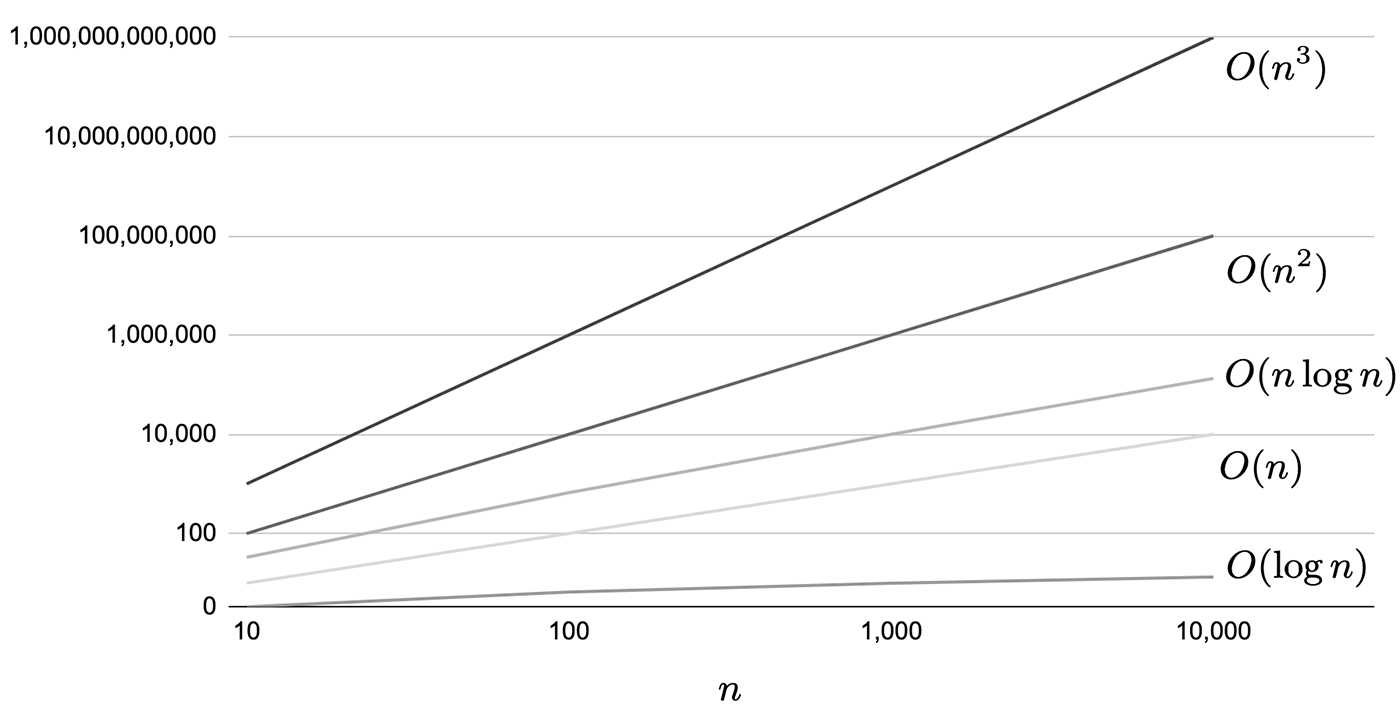
図2.36: 各計算量の対数表示による性能差比較
それぞれの計算量を示すため、いくつかコードサンプルを挙げて行きます。まず、O(1)はデータ数に依存せず一定の計算量であることを示します。
リスト2.9: O(1)のコード例
private int GetValue(int[] array) { // arrayには何らかの整数値が入っている配列とする var value = array[0]; return value; } |
このメソッドの存在意義はさておき、明らかにarrayのデータ数に依存することなく処理は一定回数(ここでは1回)で終わります。
次にO(n)のコード例を見てみましょう。
リスト2.10: O(n)のコード例
private bool HasOne(int[] array, int n) { // arrayはlength=nで、何らかの整数値が入っているとする for (var i = 0; i < n; ++i) { var value = array[i]; if (value == 1) { return true; } } } |
こちらは、整数値の入った配列に1が存在していたらtrueを返すだけの処理です。偶然arrayの最初に1が入っていたら最速で処理が終わる可能性もありますが、arrayのなかにどこにも1がない場合や、arrayの最後にはじめて1があった場合にはループは最後まで回るためn回処理をすることになります。この最悪のケースのときをO(n)として表し、データ数に応じて計算量が増えていくイメージが浮かぶことでしょう。
次にO(n^2)のときの例を見てみましょう。
リスト2.11: O(n^2)のコード例
private bool HasSameValue(int[] array1, int[] array2, int n) { // array1, array2はlength=nで、何らかの整数値が入っているとする for (var i = 0; i < n; ++i) { var value1 = array1[i]; for (var j = 0; j < n; ++j) { var value2 = array2[j]; if (value1 == value2) { return true; } } } return false; } |
こちらは二重ループで2つの配列のどこかに同じ値が含まれていたらtrueを返すだけのメソッドです。最悪のケースを考えるとすべて不一致のケースとなるため、その場合はn^2回処理が走ることになります。
余談ですが、計算量の考え方では最大次数の項のみで表現します。上記例の3つのメソッドを1回ずつ実行するメソッドを作ると、最大次数のO(n^2)になります。(O(n^2+n+1)にはなりません)
また、計算量はあくまでデータ数が十分多いときの目安であり、実計測時間と必ずしも連動するものではないことに注意しておきましょう。O(n^5)のような巨大な計算量に見えてもデータ数が少ない場合、問題にならないケースもあるため、計算量は参考にしつつも都度データ数を考慮して問題ない処理時間に収まるか測定することを推奨します。
2.6.2 基本的なコレクションとデータ構造
C#にはさまざまなデータ構造を持つコレクションクラスが用意されています。よく使うものを例に挙げつつ、おもなメソッドの計算量を踏まえてそれぞれどういうシチュエーションで採用するべきかを紹介します。
ここで紹介しているコレクションクラスにおけるメソッドの計算量についてはMSDNにすべて掲載されているため、最適なコレクションクラスを選定するときに確認できるとより安全でしょう。
List<T>
もっともよく使われているであろうList<T>です。データ構造は配列です。データの並び順が重要な場合や、インデックスによるデータの取得や更新が多い場合に用いると効果的です。逆に要素の挿入や削除が多くなる場合には操作したインデックス以降のコピーが必要になり計算量が大きくなるため、List<T>の使用を避けたほうが無難でしょう。
また、Addでキャパシティを超えようとしたときには、配列の確保メモリの拡張が行われます。メモリの拡張時は現在のCapacityの2倍を確保することになるため、AddをO(1)で使うためにも拡張を発生させずに使用できるように適切な初期値を設定して使用しましょう。
表2.6: List<T>
| メソッド | 計算量 |
|---|---|
| Add | O(1)ただしキャパシティを超えたときはO(n) |
| Insert | O(n) |
| IndexOf/Contains | O(n) |
| RemoveAt | O(n) |
| Sort | O(n\log n) |
LinkedList<T>
LinkedList<T>のデータ構造は連結リストです。連結リストは基本的なデータ構造で、各ノードが次のノードの参照を持っているようなイメージです。C#のLinkedList<T>は双方向の連結リストであるため、前後のノードへの参照をそれぞれ持っています。LinkedList<T>は、要素の追加や削除に強い特徴がありますが、配列内の特定の要素にアクセスするのは苦手です。頻繁に追加や削除を行う必要があるような一時的にデータを保持する処理を作りたいときなどに適しています。
表2.7: LinkedList<T>
| メソッド | 計算量 |
|---|---|
| AddFirst/AddLast | O(1) |
| AddAfter/AddBefore | O(1) |
| Remove/RemoveFirst/RemoveLast | O(1) |
| Contains | O(n) |
Queue<T>
Queue<T>は先入れ先出し法: FIFO(First in first out)を実現したコレクションクラスです。入力操作などを管理するときなど、いわゆる待ち行列を実装するときに用いられます。Queue<T>では循環配列が用いられています。Enqueueで要素を末尾に追加して、Dequeueで先頭の要素を取り出しつつ削除します。キャパシティを超えて追加する際には拡張が行われます。Peekは削除をせずに先頭の要素を取り出す操作です。計算量を見ても明らかなようにEnqueueとDequeueに留めて使うと高いパフォーマンスを得られますが、探索などの操作には向かないでしょう。TrimExcessはキャパシティを削減するメソッドですが、パフォーマンスチューニング観点から見ると、そもそもキャパシティが増減しないように使用できるとさらにQueue<T>の強みを活かせます。
表2.8: Queue<T>
| メソッド | 計算量 |
|---|---|
| Enqueue | O(1)ただしキャパシティを超えたときはO(n) |
| Dequeue | O(1) |
| Peek | O(1) |
| Contains | O(n) |
| TrimExcess | O(n) |
Stack<T>
Stack<T>は後入れ先出し法: LIFO(Last in first out)を実現したコレクションクラスです。Stack<T>は配列で実装されています。Pushで先頭に要素を追加し、Popで先頭の要素を取り出しつつ削除します。Peekは削除をせずに先頭の要素を取り出す操作です。よく使われる場面としては画面遷移を実装するときに遷移時に進んだ先のシーン情報をPushしておき、戻るボタンを押したときにPopするときなどが挙げられます。StackもQueueと同様にPushとPopのみを用いると高いパフォーマンスが得られます。要素の探索などは行わずに、キャパシティの増減にも注意しましょう。
表2.9: Stack<T>
| メソッド | 計算量 |
|---|---|
| Push | O(1)ただしキャパシティを超えたときはO(n) |
| Pop | O(1) |
| Peek | O(1) |
| Contains | O(n) |
| TrimExcess | O(n) |
Dictionary<TKey, TValue>
これまで紹介したコレクションは順序に意味を持つものでしたが、Dictionary<TKey, TValue>は索引性に特化したコレクションクラスです。データ構造はハッシュテーブル(連想配列の一種)で実装されています。キーに対応する値がある辞書(辞書の場合単語がキー、説明が値)のような構造です。Dictionary<TKey, TValue>はメモリを多く消費するデメリットはありますが、その分参照速度がO(1)と高速です。列挙や探索を必要とせず、値を参照することに重きを置くようなケースでとても重宝します。また、キャパシティの事前設定を必ず行いましょう。
表2.10: Dictionary<TKey, TValue>
| メソッド | 計算量 |
|---|---|
| Add | O(1)ただしキャパシティを超えたときはO(n) |
| TryGetValue | O(1) |
| Remove | O(1) |
| ContainsKey | O(1) |
| ContainsValue | O(n) |
2.6.3 計算量を下げる工夫
これまで紹介したコレクション以外にもさまざまなものが用意されています。もちろん、List<T>(配列)だけでも同様の処理を実装することは可能ですが、より適したコレクションクラスを選択することで計算量の最適化が可能になります。計算量を意識してメソッドを実装をしていくだけでも重い処理を避けることができるようになるでしょう。コード最適化における1つの切り口として、自分が作ったメソッドの計算量を確認して、より少ない計算量にできないか検討してみてはいかがでしょうか。
工夫の手段: メモ化
とある複雑な計算をしなければならないような、とても高い計算量のメソッド(ComplexMethod)があるとします。しかしどうにも計算量を減らすことができないときもあるでしょう。こうしたときに用いられる手段としてメモ化と呼ばれる手法があります。
ここでのComplexMethodは引数を与えると対応した結果が一意に返るものとします。まず、渡された引数が初回のときには複雑な処理を通します。計算後、引数と計算結果をDictionary<TKey, TValue>に入れてキャッシュしておきます。2回目以降はまずはキャッシュされてないか調べ、すでにキャッシュされていたらその結果だけを返して終了します。こうすることで、初回がどれだけ高い計算量でも2回目以降はO(1)に抑えることが可能です。もし事前に渡されうる引数がある程度決まっているようでしたら、ゲームの前に計算を済ませてキャッシュしておくことで、事実上O(1)の計算量で処理することが可能になります。